Copyright © 2000-2021 Yves MARCOUX; dernière modification de cette page: 2021-01-03.
Yves MARCOUX - EBSI - Université de Montréal
Note: Le sujet des jeux de caractères (en anglais, Character sets ou Character codes) est complexe et ramifié. Ce qui suit est, à certains égards, une simplification délibérée de la réalité, dont le but est de faire ressortir les notions les plus importantes et les plus directement applicables au traitement de l’information documentaire. Pour avoir plus de détails (sinon tous les détails), le lecteur intéressé dispose de nombreuses ressources, dont notamment l’excellent texte de Korpela: A tutorial on character code issues <https://jkorpela.fi/chars.html>.
Tout fichier stocké sur un système informatique n’est en fait rien d’autre qu’une succession de bits, c’est-à-dire de 1s et de 0s (représentés sous forme de signaux physiques, le plus souvent magnétiques, optiques ou électriques). On est rarement conscient de cela parce que, lorsqu’on ouvre un fichier avec le logiciel approprié, ce logiciel interprète les bits constituant le fichier d’une certaine façon, et nous présente le résultat de cette interprétation. Par exemple, lorsqu’on ouvre un fichier mp3 (un des nombreux formats de représentation numérique du son) avec un logiciel de lecture approprié (par exemple, RealPlayer®), ce dernier interprétera le contenu du fichier en reproduisant le son qui s’y trouve encodé selon les conventions propres au format mp3.
Il est cependant possible, et fort utile pour bien comprendre la représentation numérique de l’information, de visualiser sans interprétation le contenu d’un fichier. Ici, nous utiliserons à cette fin un programme utilitaire qui affiche le contenu de n’importe quel fichier en hexadécimal, sans aucune interprétation (il s’agit de Binary Browser de Papyrus Software <http://www.papyrussoftware.com>). L’hexadécimal ne présente pas les bits un par un, mais bien par groupes de 4, selon la correspondance suivante:
| Chiffre hexadécimal | Suite de bits correspondante |
|---|---|
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
| 4 | 0100 |
| 5 | 0101 |
| 6 | 0110 |
| 7 | 0111 |
| 8 | 1000 |
| 9 | 1001 |
| A | 1010 |
| B | 1011 |
| C | 1100 |
| D | 1101 |
| E | 1110 |
| F | 1111 |
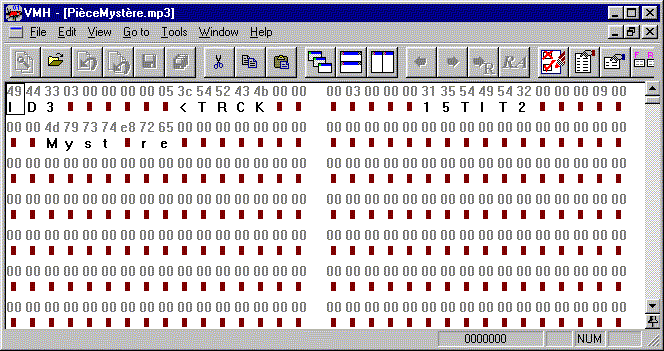
Nous pouvons ainsi regarder le début d’un fichier mp3, et voici ce que nous observons:
Une ligne sur deux de l’affichage de Binary Browser présente le contenu du fichier en hexadécimal (les autres lignes affichant le même contenu interprété comme caractères, lorsque possible, ou rectangles marron sinon). Ainsi, les 16 premiers bits de ce fichier sont 0100 1001 0100 0100, correspondant aux quatre chiffres hexadécimaux 49 44 que l’on peut lire sur la première ligne de l’affichage. Le dixième groupe de huit bits – ou octet – du fichier est constitué des bits 0011 1100, correspondant à l’hexadécimal 3C.
Pour les afficher, nous regroupons les bits 4 par 4 et les chiffres hexadécimaux 2 par 2 (comme le fait Binary Browser). Binary Browser sépare en plus les groupes de 16 octets (ou 32 chiffres hexadécimaux) en deux colonnes. Tous ces espacements ont un rôle exclusivement cosmétique, pour faciliter la lecture, et n’ont aucune signification particulière. Physiquement sur le disque, les bits forment une suite ininterrompue, sans aucune séparation, du début à la fin du fichier.
RealPlayer sait comment interpréter la séquence de bits contenue dans le fichier mp3 comme un son, et envoyer les signaux qu’il faut à la carte sonore de notre ordinateur de façon à restituer ce son. Binary Browser, lui, n’essaie même pas de faire une telle interprétation; il se contente simplement d’afficher les bits constituant le fichier, sous la forme d’une suite de chiffres hexadécimaux, chaque chiffre hexdécimal correspondant à une suite de 4 bits.
Exercice: Le vingtième bit du fichier montré ci-dessus est-il un 1 ou un 0? (Réponse: un 1.)
On peut représenter de l’information textuelle dans un fichier; dans ce cas, les différents bits constituant le fichier encodent des caractères (et non un son ou une image). Dans une optique d’échange d’information, l’utilisation d’une représentation normalisée des caractères a un grand intérêt (tout comme l’utilisation d’une représentation normalisée du son, tel le format mp3, a un grand intérêt pour le partage de sons; c’est la base même des plate-formes de diffusion musicale comme Spotify, Bandcamp, Google Play Musique, etc.).
Suivant Korpela, nous définissons un jeu de caractères (en anglais character set) comme une combinaison de trois éléments:
Le premier élément, le répertoire de caractères, est simplement l’ensemble des caractères représentables dans le jeu.
Le deuxième élément, la numérotation des caractères, attribue simplement un numéro à chaque caractère du répertoire. Les numéros attribués ne sont pas nécessairement consécutifs; ils commencent habituellement, mais pas toujours, à 0 (et non à 1).
Le troisième élément, le codage des numéros, détermine comment chaque numéro de caractère est représenté concrètement comme séquence de bits.
En connaissant les trois éléments qui constituent un jeu de caractères, on sait donc exactement quels caractères peuvent être représentés avec ce jeu, et aussi exactement comment toute suite de caractères représentables est stockée concrètement comme suite de bits dans un fichier.
Voici un exemple de jeu de caractères: l’ASCII pur sur 8 bits. L’appellation « pur » le distingue d’autres jeux qui sont en fait des ASCII étendus, dont nous parlerons plus tard.
|
|
|
|
Comme on peut voir, les numéros de ce jeu vont de 0 à 127; le répertoire contient donc 128 caractères. Dans ce jeu, les numéros utilisés dans la numérotation sont consécutifs, mais ce n’est pas le cas de tous les jeux de caractères. On peut voir également que le codage fait correspondre à chaque numéro de caractère un suite de 8 bits. L’ASCII pur sur 8 bits est donc un jeu de caractères dans lequel chaque caractère est représenté par un code à 8 bits, d’où la partie « sur 8 bits » de son nom.
Notons qu’il existe 28 = 256 combinaisons possibles de 8 bits. Un exemple de combinaison est 0000 0000; un autre est 1010 1010; etc. En utilisant des codes de 8 bits, on pourrait donc théoriquement représenter 256 caractères différents, c’est-à-dire accomoder un répertoire contenant jusqu’à 256 caractères. L’ASCII pur sur 8 bits n’utilise donc pas toutes les possiblités que lui offre son codage; en fait, il n’en utilise que la moitié!
L’ASCII pur sur 8 bits, tel que présenté ici, correspond à la International Reference Version de la norme ISO « ISO/IEC 646:1991 Information technology -- ISO 7-bit coded character set for information interchange », ce qui est parfois abrégé ISO 646 IRV. ISO est l’Organisation internationale de normalisation <https://www.iso.org/>. L’ASCII pur sur 8 bits correspond également à ce qu’on appelle communément le US-ASCII.
Supposons qu’un fichier contient la chaîne de caractères « Ca va? Ca va! » codée selon l’ASCII pur sur 8 bits. Voici de quoi aurait l’air ce fichier, tel que présenté par Binary Browser:
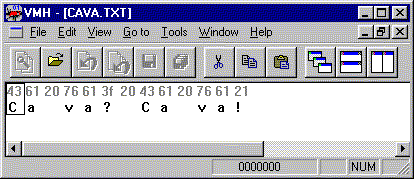
Les caractères contenus dans un répertoire sont de deux types: les caractères graphiques (ou visibles, ou imprimables, ou affichables) et les caractères non graphiques (ou de contrôle, ou de fonction). Dans le répertoire de l’ASCII pur sur 8 bits, 34 des caractères sont des caractères de contrôle, les 94 autres sont des caractères graphiques.
Dans la table ci-dessus, les caractères de contrôle sont indiqués par un code mnémonique de deux lettres ou plus, entre [crochets], dans la colonne Caractère. Ce code mnémonique est en fait une abréviation du nom anglais de la fonction représentée par le caractère; par exemple: SP = Space = Espace; CR = Carriage Return = Retour de chariot; LF = Line Feed = Changement de ligne; HT = Horizontal Tabulation = Tabulation horizontale.
Les caractères de contrôle servent à contrôler l’affichage ou la mise en page du texte sur l’équipement de restitution: écran, imprimante, etc. De nos jours, cependant, il existe des façons beaucoup plus flexibles que les caractères de contrôle pour contrôler l’affichage ou la mise en page d’un texte, de sorte que de nombreux logiciels (en fait, la plupart) « n’obéissent » plus aux caractères de contrôle, sauf ceux correspondant aux fonctions les plus élémentaires: SP, CR, LF et HT. Pour des raisons historiques, on retrouve les 34 caractères de contrôle de l’ASCII pur dans le répertoire de la plupart des jeux de caractères actuellement en usage. Cependant, les seuls couramment utilisés sont ceux correspondant aux quatre fonctions mentionnées ci-dessus.
À partir de maintenant, nous désignerons par « ASCII pur » la combinaison du répertoire et de la numérotation des caractères de l’ASCII pur sur 8 bits (voir table ci-dessus). L’« ASCII pur » n’est donc pas en soi un jeu de caractères, mais il établit un répertoire de caractères ainsi qu’une numérotation des caractères de ce répertoire. Il n’y manque qu’un codage pour établir un jeu de caractères spécifique. L’ASCII pur sur 8 bits, lui, est un jeu de caractères, fondé sur l’ASCII pur, c’est-à-dire ayant l’ASCII pur comme répertoire et numérotation.
ASCII signifie American Standard Code for Information Interchange. L’ASCII pur a le défaut de ses origines: il ne convient vraiment que pour des textes en langue états-unienne; par exemple, le seul symbole de devise monétaire qu’on y retrouve est celui du dollar états-unien « $ »; également, aucune lettre avec signe diacritique (accent, cédille, etc.) ne s’y retrouve.
Au début de l’informatique, pratiquement tous les jeux de caractères utilisés étaient fondés sur l’ASCII pur. À cette époque, les utilisateurs non états-uniens ne voyaient pas d’inconvénients à se passer des symboles propres à leur langue lorsqu’ils utilisaient l’informatique. Il y eut toute une période où l’on considérait « normal » que des textes non anglais soient dépourvus de leurs signes diacritiques. Avec le temps, cependant, il y eut beaucoup de pression des utilisateurs pour pouvoir travailler dans d’autres langues que l’anglais états-unien. Les producteurs de matériel et de logiciels dûrent donc développer des jeux de caractères fondés sur autre chose que l’ASCII pur.
Une façon toute naturelle de procéder, pour palier les faiblesses de l’ASCII pur, est de définir un jeu de caractères qui inclut l’ASCII pur, tout en y ajoutant de nouveaux caractères. C’est ce qu’on appelle étendre l’ASCII pur. Plus précisément, nous définissons un ASCII étendu comme étant un jeu de caractères dont:
Notons tout de suite que, à cause du point (2) ci-dessus, le répertoire d’un ASCII étendu peut contenir au maximum 28 = 256 caractères différents.
Il y a en fait deux problèmes avec les ASCII étendus. D’abord, comme ils ont été développés au début de la micro-informatique (début des années 1980), à une époque où l’importance de la normalisation n’était pas encore pleinement perçue et, le plus souvent, par des groupes isolés, ils ne sont pas, pour la plupart, normalisés. Par ailleurs, comme un ASCII étendu ne peut accomoder que 256 caractères au total, chacun ne peut convenir qu’à quelques langues écrites. Aucun ASCII étendu unique ne peut représenter tous les caractères en usage dans toutes les langues écrites. Certaines langues, comme par exemple le chinois, qui compte des dizaines de milliers de caractères, ne pourraient même pas être représentées en entier avec un seul ASCII étendu!
Malgré leurs lacunes (en fait, on pourrait dire à cause de leurs lacunes), les ASCII étendus ont littéralement pullulé, à une certaine époque. Dans certains cas, plusieurs différents ont été développés pour une même langue; par exemple, on ne compte pas moins de cinq ASCII étendus distincts pour l’alphabet cyrillique (utilisé, entre autres, dans la langue russe).
Malgré cette prolifération incontrôlée, il y a quand même eu des efforts de normalisation. Ainsi, quelques ASCII étendus normalisés ont vu le jour dans les années 1980. Parmi ceux-ci, les plus dignes de mention sont ceux de la série ISO 8859. Il s’agit de quinze jeux normalisés par ISO, couvrant un grand nombre de langues écrites. Tous ont été révisés en 1998 ou 1999, sauf le ISO 8859-7, dont la dernière révision remonte à 1987.
Un de ces quinze jeux joue un rôle fondamental dans l’informatique moderne; c’est le « ISO/IEC 8859-1:1998 Information technology -- 8-bit single-byte coded graphic character sets -- Part 1: Latin alphabet No. 1 ». Ce jeu est communément appelé « ISO-Latin-1 » ou encore « ISO-8859-1 ». Son importance vient entre autres du fait que c’est le jeu de caractères par défaut des fichiers du Web.
Évidemment, la première partie de l’ISO-Latin-1 (les numéros 0 à 127) coïncide avec l’ASCII pur sur 8 bits, puisqu’il s’agit d’un ASCII étendu. La seconde partie (comprenant les numéros 128 à 255) est comme suit:
|
|
|
|
Comme on peut voir, la seconde partie de l’ISO-Latin-1 comprend 34 caractères de contrôle, soit les numéros 128 à 160 et le numéro 173. Le caractère numéro 160 correspond à la fonction NBSP = No-Break Space = Espace insécable. Le caractère numéro 173 correspond à la fonction SHY = Soft Hyphen = Trait d’union discrétionnaire.
Deux grands absents de l’ISO-Latin-1 sont la ligature oe « œ », essentielle à la typographie française correcte, et le symbole de l’euro « € ».
Le jeu de caractères utilisé à l’interne par Windows (versions occidentales) est également un ASCII étendu; techniquement, on l’appelle la « page de codes 1252 ». Il ne s’agit pas d’un jeu normalisé, bien qu’il soit très répandu. C’est le jeu de caractères utilisé par défaut par le Bloc-notes (NotePad) de Windows.
Nous ne présenterons pas les caractéristiques de la page de codes 1252; nous nous contenterons de dire qu’elle est très près de l’ISO-Latin-1. En fait, les seules différences se situent entre les numéros 128 et 159; la page de codes 1252 y inclut quelques caractères graphiques, dont la ligature oe « œ » et le symbole de l’euro « € », alors que l’ISO-Latin-1 n’y contient que des caractères de contrôle.
Note: Ce que nous présentons d’Unicode ne correspond pas nécessairement à la dernière version de la norme; certains points ont pu changer dans la version courante. Se référer au site Unicode <https://www.unicode.org> pour tous les détails.
Contrairement à l’ASCII pur sur 8 bits, l’ISO-Latin-1 exploite complètement les possiblités de son codage: son répertoire possède 256 caractères, le maximum permis par un codage sur 8 bits. Pour aller plus loin, et représenter tous les caractères des langues écrites dans un même jeu, il faut se libérer du codage sur 8 bits. C’est ce que l’Unicode propose.
Unicode a été développé pendant les années 1980 et au début des années 1990 par un consortium de groupes d’intérêt dans le domaine de l’échange d’information textuelle. L’objectif est de pouvoir représenter la totalité des caractères des langues écrites dans un seul et même jeu de caractères. C’est une norme en évolution, qui, en 2014, en est à sa version 6.3. Par une entente datant de 1991 entre ISO et le Consortium Unicode, Unicode coïncide à peu près exactement avec la norme « ISO/IEC 10646-1:1993 Information technology -- Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane » (voir les détails au <https://www.unicode.org/faq/unicode_iso.html>).
Paradoxalement, le vocable Unicode, sans autre qualificatif, réfère à un répertoire de caractères et à une numérotation, mais pas à un codage particulier. Donc, Unicode en soi ne désigne pas un jeu de caractères en bonne et due forme, mais simplement un répertoire spécifique et une numérotation spécifique, auxquels il faut ajouter un codage pour obtenir un jeu de caractères.
La norme Unicode propose en fait plusieurs codages différents, qui portent différents noms; nous en mentionnerons trois: UTF-8, UTF-16-BE et UTF-16-LE. La mention Unicode à laquelle on adjoint le nom d’un codage désigne sans équivoque un jeu de caractères particulier. Ainsi, par exemple, Unicode-UTF-8 désigne le jeu de caractères comprenant le répertoire Unicode, la numérotation Unicode et le codage UTF-8.
La numérotation Unicode utilise des numéros entre 0 et 65535. Théoriquement, le répertoire Unicode pourrait donc contenir 65536 caractères; à ce jour, cependant, il en comprend autour de 50000. La quasi-totalité des langues écrites sont couvertes, incluant le chinois, l’arabe et l’hébreux.
Unicode a été conçu comme une extension du ISO-Latin-1, dans le sens suivant:
Évidemment, il est hors de question de présenter ici l’entièreté du répertoire Unicode. Par le point (2) ci-dessus, nous savons déjà que les numéros 0 à 255 correspondent à l’ISO-Latin-1, dont les tables sont données ci-dessus. À titre d’exemple de ce qu’Unicode ajoute par rapport à l’ISO-Latin-1, voici la partie correspondant aux numéros 256 à 383:
 |
Vous noterez que les numéros des caractères ne sont pas donnés tels quels, mais que, par ailleurs, un code de quatre chiffres hexadécimaux est donné pour chaque caractère. Ce code correspond bien à un des codages Unicode, mais nous y reviendrons plus tard.
Si on était intéressé à connaître le numéro d’un caractère, on pourrait facilement le trouver à partir du code hexadécimal du caractère; en effet, il suffit de convertir le code de l’hexadécimal au décimal, conversion qu’on peut effectuer facilement à l’aide d’une calculatrice scientifique (par exemple, celle de Windows). Ainsi, les caractères dont les codes hexadécimaux sont 0152 et 0153 occupent les numéros 338 et 339; notons qu’il s’agit des ligatures oe majuscule et minuscule. Le symbole de l’euro n’est pas dans cette partie de la numérotation; il occupe en fait le numéro 8364 (en décimal).
Le codage UTF-16-BE est l’un des codages préconisés par la norme Unicode. Ce codage associe simplement un code de 16 bits (2 octets) à chaque caractère. Dans la table ci-dessus, de même que dans les autres tables similaires que le Consortium Unicode publie pour l’ensemble d’Unicode, le code UTF-16-BE d’un caractère est donné directement avec le caractère, sous forme de quatre chiffres hexadécimaux. Ainsi, selon le codage UTF-16-BE, le code du caractère « Ŝ » (S accent circonflexe) correspond à la suite de quatre chiffres hexadécimaux 01 5C, et est donc la suite de 16 bits suivante:
0000 0001 0101 1100
Pour les caractères qui ont un numéro entre 0 et 255, on pourrait bien sûr connaître leur code en consultant la table Unicode correspondante. Cependant, on peut aussi utiliser les tables du ISO-Latin-1, puisque, pour ces caractères, le code UTF-16-BE est identique au code ISO-Latin-1 précédé des 8 bits 0000 0000 (i.e., des deux chiffres hexadécimaux 00). Par exemple, le code UTF-16-BE de « a » est 00 61 en hexadécimal, c’est-à-dire:
0000 0000 0110 0001
en bits.
Ainsi, par exemple, si un fichier contient la chaîne de caractères « Ŝvoboda », codée selon l’Unicode-UTF-16-BE, Binary Browser nous le montrerait comme suit:
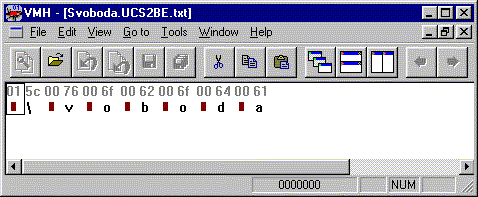
Profitons-en pour mentionner que l’affichage des octets sous forme de caractères que Binary Browser tente de faire (sous les lignes de chiffres hexadécimaux) se fait selon l’ASCII pur sur 8 bits. Seuls les caractères graphiques et l’espace (selon l’ASCII pur sur 8 bits) sont affichés; les caractères non graphiques sont représentés visuellement par des petits rectangles pleins.
Évidemment, si un fichier ne contient pas des caractères codés selon l’ASCII pur sur 8 bits, il est normal que cette tentative d’affichage ne donne rien d’intéressant. C’était le cas lorsque nous avons visualisé un fichier mp3, plus tôt. C’est pour cela, aussi, que Binary Browser nous montre un « \ » sous le 5C; en effet, ce code correspond bien au caractère « \ » dans l’ASCII pur sur 8 bits.
Le jeu de caractères Unicode-UTF-16-BE est parfois appelé simplement "Unicode big endian" dans Windows (par exemple, dans le Bloc-notes).
Le codage UTF-16-LE est pratiquement identique au codage UTF-16-BE, la seule différence étant que les deux octets de chaque code sont inversés. Par exemple, le code UTF-16-BE correspondant au « A » est 00 41 (en hexadécimal); le code UTF-16-LE du même caractère est donc 41 00, soit les mêmes deux octets, mais inversés.
Le codage UTF-16-LE existe pour des raisons historiques, parce que certains micro-processeurs ne pouvaient stocker leurs données qu’en inversant les octets! Ces machines étaient qualifiées de little-endian (d’où le « LE »), par rapport aux autres, qu’on qualifiait de big-endian (d’où le « BE »).
Le jeu de caractères Unicode-UTF-16-LE est parfois appelé simplement "Unicode" dans Windows (par exemple, dans le Bloc-notes).
Le codage UTF-8 d’Unicode est très important, surtout parce que l’Unicode-UTF-8 est le jeu de caractères par défaut des fichiers XML (eXtensible Markup Language, recommandation du W3C). L’UTF-8 est un codage à longueur variable, en ce sens que certains codes ont une longueur d’un octet, certains autres ont une longueur de deux octets, et certains autres ont une longueur de trois octets.
La seule caractéristique importante à souligner du UTF-8 est qu’il fait correspondre exactement les mêmes codes que l’ASCII pur sur 8 bits aux numéros 0 à 127. À cause de cette caractéristique, tout fichier contenant un texte codé selon l’ASCII pur sur 8 bits se trouve aussi, ipso facto, à contenir le même texte codé selon Unicode-UTF-8!
Il existe une convention, préconisée par la norme Unicode, qui permet de détecter si un fichier est codé en UTF-16-BE, UTF-16-LE ou UTF-8. Cette convention est d’inclure comme premier caractère du fichier le caractère de contrôle [ZWNBSP] = Zero-width no-break space = Espace insécable de largeur nulle. Ce caractère n’apparaît pas dans les tables présentées ci-dessus; il se situe au numéro 65279 du répertoire Unicode et son code UTF-16-BE est FE FF.
Suivant cette convention, si on sait qu’un fichier est codé en UTF-16-BE, en UTF-16-LE ou en UTF-8, sans savoir lequel des trois, on peut déterminer le codage exact en regardant les deux ou trois premiers octets du fichier: si les deux premiers octets sont FE FF, alors le fichier est codé en UTF-16-BE; s’ils sont FF FE, alors le fichier est codé en UTF-16-LE; si les trois premiers octets sont EF BB BF, alors le fichier est codé en UTF-8. Ces deux ou trois octets, qui représentent le caractère de contrôle [ZWNBSP] au début d’un fichier, sont aussi appelés Byte-order mark ou BOM. L’utilisation des "byte-order marks" est aujourd’hui très répandue dans les applications qui prennent en charge Unicode. Par exemple, depuis Windows 2000, l’application Bloc-notes les utilise.
| Premiers octets du fichier (en hexadécimal): | Indiquent le codage: |
|---|---|
| FE FF | UTF-16-BE |
| FF FE | UTF-16-LE |
| EF BB BF | UTF-8 |
Le caractère [ZWNBSP], lorsque présent comme premier caractère d’un fichier, n’est pas considéré comme faisant partie du contenu textuel du fichier. Il ne sert vraiment qu’à indiquer le codage utilisé.
Par exemple, supposons qu’on sait que le fichier suivant est codé soit en UTF-16-BE, soit en UTF-16-LE, soit en UTF-8, sans savoir lequel des trois. On observe les deux premiers octets: FF FE, et on conclut que le fichier est codé en UTF-16-LE:
FF FE 43 00 53 01 75 00 72 00
Exercice: Traduisez ce fichier en chaîne de caractères, selon l’Unicode-UTF-16-LE. Réponse: « Cœur » (notez que le premier caractère, [ZWNBSP], n’est pas considéré comme faisant partie du contenu textuel).
Un fichier texte selon un jeu de caractères donné, est un fichier ne contenant que des codes qui correspondent, dans ce jeu, à des caractères graphiques ou à un des caractères de contrôle [SP], [CR], [LF], [HT]. Le caractère [ZWNBSP] est également admis, mais seulement comme premier caractère d’un fichier, où il sert à indiquer le codage Unicode utilisé (UTF-16-BE, UTF-16-LE ou UTF-8).
Le fichier suivant, présenté ici en hexadécimal, est un exemple de fichier texte selon le jeu ASCII pur sur 8 bits:
41 6C 69 20 42 61 62 61
En effet, si l’on interprète les octets de ce fichier comme des codes selon le jeu ASCII pur sur 8 bits, on constate que chacun des codes contenus dans le fichier correspond à un caractère graphique ou à un des caractères de contrôle admis (en l’occurrence, l’espace [SP], correspondant au code 20).
Exercice: Traduisez ce fichier en chaîne de caractères selon l’ASCII pur sur 8 bits. Réponse: « Ali Baba ».
Notons que la notion de fichier texte, sans référence à un jeu de caractères spécifique, n’a pas de sens. En effet, un même fichier pourrait très bien être un fichier texte selon un certain jeu, mais pas selon un autre. Par exemple, le fichier Svoboda.UCS2BE.txt, visualisé ci-dessus avec Binary Browser, est un fichier texte selon Unicode-UTF-16-BE, mais n’est pas un fichier texte selon l’ASCII pur sur 8 bits (assurez-vous de bien comprendre cette affirmation).
Est-ce qu’un document en format Microsoft Word est un fichier texte? Qu’en est-il des documents de n’importe quel autre logiciel de traitement de texte?
Bien sûr, pour que ces questions aient un sens, il faudrait préciser un jeu de caractères. Mais, d’emblée, on peut dire que la réponse aux deux questions est non. Les logiciels de traitement de texte ne stockent pas leurs documents sous forme de fichiers texte. Ils utilisent des représentations de l’information qui leurs sont exclusives et qui n’ont rien d’un simple jeu de caractères. Cela leur permet, entre autres, de conserver une foule de renseignements sur les documents, comme par exemple, la langue du document (pour la correction orthographique), les polices utilisées, les images intégrées au document, etc. Bien sûr, le texte du document se trouve représenté quelque part dans le document, mais il est « noyé » dans un tas d’autres données, et il est représenté d’une façon que seul ce logiciel de traitement de texte spécifique peut interpréter correctement avec certitude.
Pour nous convaincre qu’un document de traitement de texte n’est pas un fichier texte, regardons dans Binary Browser le début d’un document Word:
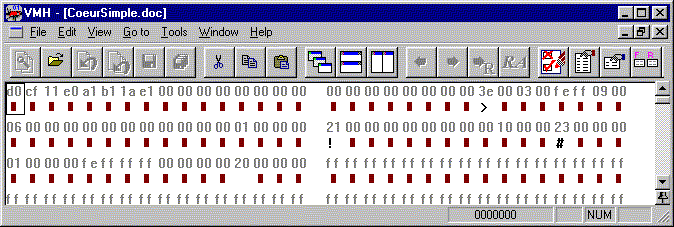
Pas besoin d’aller très loin pour apercevoir toute une série d’octets à zéro (hexadécimal 00). Est-ce qu’une suite de deux octets à zéro peut être le code d’un ou plusieurs caractères graphiques ou [SP], [CR], [LF], [HT] dans un des jeux de caractères dont nous avons parlé jusqu’ici? Si on analyse la question, on se rend compte que, dans tous les jeux présentés jusqu’ici, la suite de deux octets 00 00 représente soit un seul caractère [NUL], soit une suite de deux caractères [NUL]. Comme ce caractère n’est ni graphique, ni un des caractères de contrôle admis dans un fichier texte, on conclut effectivement que ce fichier n’est un fichier texte selon aucun des jeux introduits ci-dessus.
Morale? De façon générale, c’est une erreur de prendre pour acquis que le texte d’un document de traitement de texte est représenté selon un certain jeu de caractères précis dans le fichier. Par exemple, la fonction de recherche de fichiers de Windows, avec un critère de contenu textuel, recherche des caractères selon deux jeux spécifiques: celui de Windows et celui du DOS (qui est en général différent de celui de Windows). Il ne faut pas s’étonner si parfois, avec cette fonction, on ne retrouve pas exactement les fichiers recherchés: le texte dans les documents de traitement de texte n’est pas nécessairement représenté selon un de ces deux jeux.
Malheureusement, il ne suffit pas de disposer d’un logiciel capable de traiter un jeu de caractères donné pour automatiquement être capable de visualiser à l’écran ou imprimer les fichiers texte selon ce jeu; il faut aussi disposer d’une police de caractères (en anglais font) adéquate. Ainsi, par exemple, les versions récentes de Word sont capables de lire des fichiers texte Unicode-UTF-16 (BE ou LE), mais on ne verra correctement les caractères que si l’on a installé une police de caractères Unicode au niveau du système d’exploitation et si on sélectionne cette police dans Word.
Une police de caractères associe des dessins de caractères à un répertoire de caractères et à une numérotation spécifiques. La plupart des polices incluses dans Windows sont conformes à la page de codes 1252 de Windows, mais certaines sont conformes à d’autres répertoires et numérotations.
Si vous disposez d’une version assez récente du système d’exploitation Windows, vous pouvez en apprendre plus sur les polices installées sur votre système en ouvrant le Bloc-notes puis en faisant Format → Police. Regardez en particulier les choix présents sous Script; ces choix ne sont pas toujours les mêmes pour toutes les polices. Vous pouvez aussi cliquer sur le lien vers d’Autres polices.
Une police Unicode est une police conforme au répertoire et à la numérotation Unicode. Une mise en garde concernant les polices Unicode: souvent, elles n’incluent pas un dessin pour tous les caractères du répertoire, mais seulement pour un sous-ensemble, habituellement une ou quelques langues spécifiques (en plus des caractères ISO-Latin-1, évidemment).
Les polices de caractères sont des œuvres protégées par le droit d’auteur. On ne peut donc pas simplement les échanger comme on échange des documents de traitement de texte. Si, par exemple, je crée un document Word qui exige une police spéciale que j’ai achetée, je peux distribuer mon document comme bon me semble, mais je ne peux pas distribuer la police spéciale qui est nécessaire à son bon visionnement. Évidemment, cela pose des problèmes additionnels pour le partage d’information! Il vaut donc toujours mieux, dans la mesure du possible, n’utiliser que des polices « standard », c’est-à-dire qui sont distribuées gratuitement avec les systèmes d’exploitation les plus populaires (les polices de la famille « Times » étant de bons exemples de telles polices).
Même si les sujets traités ici peuvent paraître éloignés de la bibliothéconomie, ils en sont en fait très proches. Dès qu’on se détache du modèle de la bibliothèque autarcique, coupée du reste du monde, on se heurte au problème de l’interopérabilité des données, et, ultimement, à celui des jeux de caractères.
Ce n’est pas sans raison, d’ailleurs, que l’American Library Association (ALA) a elle-même développé son propre jeu de caractères, au tournant des années 1960-1970. En effet, la bibliothéconomie a été parmi les premiers domaines d’application de l’informatique confrontés aux échanges internationaux d’information numérique, et elle a dû développer ses propres solutions, à une époque où aucune solution normalisée toute faite n’existait. Ce jeu de caractères a ultérieurement été intégré au format d’échange de données catalographiques USMARC <https://www.loc.gov/marc/> et il fait, encore aujourd’hui, l’objet de recherches et de développements, auxquels participe la Bibliothèque du congrès états-unien <https://www.loc.gov/>. Aujourd’hui, bien sûr, la problématique est d’abord et avant tout d’assurer un passage en douceur vers Unicode. D’ailleurs, certaines parties d’Unicode ont été inspirées des travaux préalables de l’ALA !