Université de Montréal, EBSI
BLT6052 Informatique documentaire
Copyright © 2000 Yves MARCOUX
Nous présentons ici un scénario type de la naissance et de la vie d'une base de données documentaire. Chaque cas réel aura ses particularités, et donc ses divergences par rapport à ce scénario type. Ce dernier nous servira cependant de point de référence. Dans ce scénario, les mots qui définissent des concepts importants sont mis en caractères gras.
Une base de données documentaire est une base de données qui contient de l'information sur des documents, c'est-à-dire au sujet de documents. Nous ne définirons pas précisément ce qu'est un document; il est impossible de donner une définition suffisamment large pour couvrir tout ce qui peut être considéré comme un "document". Disons simplement que la plupart du temps, l'une des deux définitions suivantes pourrait convenir:
(1) Un document est la représentation dans un système de symboles quelconque (par exemple: une langue écrite, des dessins, des sons, etc.) du résultat d'un acte de création intellectuelle pouvant être considéré comme monolithique, atomique ou indivisible.
(2) Un document est le contenu intellectuel d'un support d'information quelconque (par exemple: un livre, un disque, etc.) dont l'acquisition, la transmission ou la manipulation en général peut être considérée comme une opération monolithique, atomique ou indivisible.
Certes, ces définitions sont vagues à souhait; nous espérons tout de même qu'elles permettront au lecteur de se faire (ou de confirmer) une idée intuitive de ce qui doit être considéré comme un "document".
Aussi curieux que cela puisse paraître, nous considérons le texte intégral d'un document écrit comme de l'information "au sujet" du document. Cette façon de voir les choses n'est pas incompatible avec les définitions ci-dessus; de plus, c'est une façon d'uniformiser et de simplifier la terminologie. Ainsi, une base de données contenant le texte intégral de documents sera considérée sans scrupule comme une base de données documentaire.
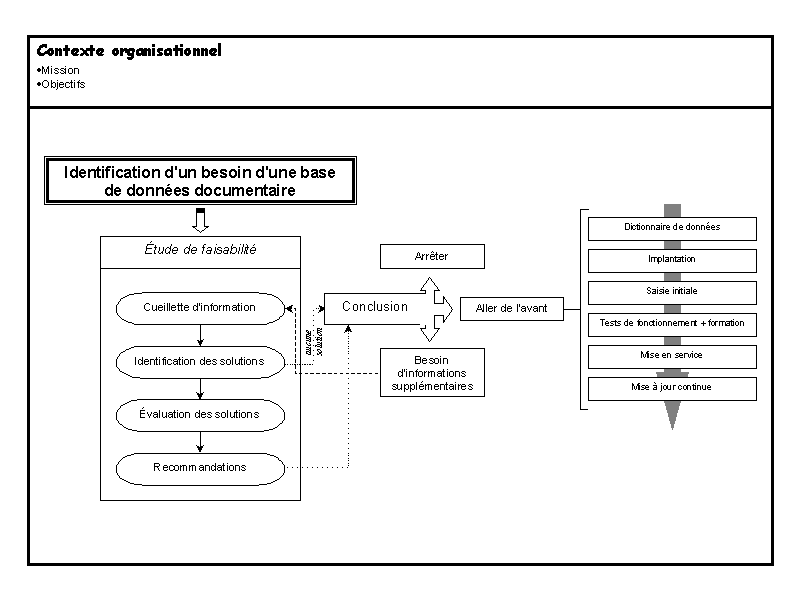
Un projet de création de base de données documentaire est conçu et mené par et pour une organisation. Les gestionnaires de l'organisation sont les premiers responsables du projet, ils le supervisent et prennent toutes les décisions qui en déterminent le déroulement. Certaines étapes du projet sont cependant confiées à des personnes (de l'organisation ou engagées à contrat pour l'occasion) désignées comme responsables de ces étapes.
Toute organisation a une mission (sociale ou autre) et des objectifs, en fonction desquels les gestionnaires dirigent l'organisation. L'idée d'un projet de création de base de données documentaire naît lorsque les gestionnaires d'une organisation ont des raisons de croire qu'une base de données documentaire pourrait aider de façon significative l'organisation à remplir sa mission ou à atteindre ses objectifs. Ils prennent alors la décision de faire réaliser une étude de faisabilité.
Le principal but de l'étude de faisabilité est de déterminer si effectivement une base de données documentaire pourrait apporter des gains nets à l'organisation, et le cas échéant, de prédire le mieux possible l'ampleur de ces gains. La conclusion d'une étude de faisabilité peut être de trois types:
(1) Le bien-fondé d'une base de données documentaire est établi, avec recommandation d'aller de l'avant. Au moins une façon de faire est alors proposée.
(2) Il est démontré qu'une base de données documentaire n'entraînerait pas de gains nets véritables pour l'organisation; on recommande alors de ne pas aller de l'avant, et des alternatives peuvent être suggérées.
(3) Il est déterminé que de l'information additionnelle substantielle est requise pour qu'on puisse établir clairement le bien-fondé d'une base de données documentaire, ou pour déterminer la meilleure façon de la réaliser. La nature de l'information manquante est précisée, et des moyens pour la recueillir sont proposés.
Il est donc clair qu'avant la fin de l'étude de faisabilité, le projet comme tel de création d'une base de données documentaire n'existe pas encore véritablement. Cependant, si la conclusion de cette étude est qu'il faut aller de l'avant, et après décision à cet effet de la part des gestionnaires, le projet voit officiellement le jour.
Comme bien des processus de gestion, l'étude de faisabilité peut se diviser en quatre étapes: cueillette d'information, identification des solutions possibles, évaluation de ces solutions, et formulation de recommandations. Les deux dernières étapes supposent qu'au moins une solution possible a été identifiée; si tel n'est pas le cas, ces deux étapes sont remplacées par la formulation d'une conclusion appropriée. Dans ce scénario, nous supposerons qu'au moins une solution possible est identifiée (autre que le statu quo, qui dans certains cas est la meilleure solution).
Pour être en mesure d'arriver à une conclusion, le responsable de l'étude de faisabilité doit:
(1) Établir à quels objectifs particuliers de l'organisation la base devrait répondre. Au besoin, procéder à des rencontres avec les gestionnaires.
(2) Établir avec précision les contraintes particulières qui devraient être respectées par une éventuelle base de données. Par exemple: budget pré-établi, utilisation imposée de matériel ou logiciels déjà disponibles, contraintes de temps ou d'espace physique, compatibilité obligatoire avec d'autres systèmes utilisés par l'organisation, exigences de confidentialité et/ou sécurité, objectifs de performance prédéterminés (temps de réponse, etc.)
(3) Établir précisément comment s'intégrerait la base de données dans le fonctionnement de l'organisation: qui utiliserait la base, comment, pourquoi? Quel est le profil de l'utilisateur type? Au besoin, interviewer des membres de l'organisation; éventuellement, faire remplir des questionnaires.
(4) Recenser tous les documents qui pourraient éventuellement figurer dans la base (cette étape est parfois appelée analyse de l'existant documentaire). Ici aussi, recourir à des entrevues ou à un questionnaire, au besoin.
Dans cette étape, le responsable de l'étude de faisabilité examine, à la lumière de l'information recueillie, les différentes formes que pourrait prendre une éventuelle base de données, et les différentes modalités d'opération et d'utilisation qu'elle pourrait avoir.
Chacun des "renseignements" (au sens large) que l'on devrait donner à quelqu'un, si l'on voulait lui expliquer la forme exacte d'une base de données ainsi que ses modalités d'opération et d'utilisation, constitue ce qu'on appelle un paramètre de cette base de données. La présente étape de l'étude de faisabilité revient donc à examiner l'ensemble des choix possibles pour chacun des paramètres d'une éventuelle base de données. Des exemples de paramètres sont donnés un peu plus loin, et devraient aider le lecteur à se faire une idée de la nature des différents paramètres d'une base de données.
Un des paramètres les plus importants, pour toute base de données, est le modèle de données selon lequel la base est construite. Ce paramètre est important pour plusieurs raisons, l'une d'elles étant qu'il détermine directement la structure de l'information que l'on peut stocker dans la base.
Un modèle de données peut se comparer à un jeu de construction. Tout comme la forme finale des constructions que l'on peut faire dépend directement des caractéristiques du jeu utilisé (la forme des blocs de base et les différentes façons dont ils peuvent s'emboîter), de la même façon, la forme finale que l'on peut donner à une base de données dépend directement du modèle de données utilisé.
En plus de déterminer les choix possibles pour la structure de la base, le modèle de données détermine les choix possibles pour plusieurs autres paramètres, comme par exemple le logiciel d'implantation; il s'agit donc d'un paramètre très fondamental pour une base de données.
Les différents choix pertinents pour le modèle de données d'une base de données documentaire incluent: le modèle relationnel, le modèle textuel (aussi appelé modèle du fichier plat), le modèle relationnel+texte, le modèle de l'hyper-texte et celui de l'hyper-média. Ce sont, à l'heure actuelle, les modèles les plus appropriés aux bases de données documentaires, entre autres parce qu'il existe de nombreux progiciels basés sur ces modèles. Les modèles entités-relations et orienté-objet sont des exemples d'autres modèles, moins répandus dans le domaine des bases de données documentaires.
En fait, le modèle de données que l'on choisit pour une base de données détermine non seulement les choix possibles pour plusieurs autres paramètres, mais également la nature même des paramètres qui doivent être fixés lors de la conception de la base. Ainsi, par exemple, si l'on choisit le modèle relationnel pour une base de données, on doit considérer une foule de paramètres qui seraient sans objet dans le modèle textuel.
Pour des raisons que nous présenterons sous peu, notre choix s'arrête sur le modèle textuel. Dans ce cas, les paramètres qui doivent être considérés incluent minimalement les suivants (selon les circonstances, d'autres pourraient s'ajouter).
Paramètres à considérer
(1) Nom de la base de données (paramètre crucial, mais souvent négligé).
(2) "Politique éditoriale": détermination de la couverture exacte de la base, c'est-à-dire d'une caractéristique (ou conjonction de caractéristiques) à la fois commune et exclusive aux documents devant figurer dans la base.
(3) Modèle de données (par hypothèse dans le présent scénario: le modèle textuel).
(4) Clé primaire des fiches: format, signification, responsabilité de l'attribution.
(5) Type de description des documents (bibliographique, catalographique).
(6) Champs à valeur ajoutée: nature (texte intégral, résumé, descripteurs, etc.) et responsabilité de la détermination du contenu.
(7) Autres champs (date, statut, note, etc.): nature, utilité.
(8) Bordereaux de saisie ou d'affichage requis.
(9) Règles d'écriture particulièrement importantes.
(10) Validations particulièrement importantes.
(11) Types de recherche requis sur les principaux champs (par mots, par contenu tel quel, par date etc.)
(12) Formats d'importation et/ou d'exportation à supporter.
(13) Rapports requis (bibliographies, catalogues, etc.): nature, modalités de diffusion.
(14) Mode d'accès à la base par les usagers: direct, réseau, par personne interposée (service de référence).
(15) Procédures d'alimentation de la base (télédéchargement, bordereaux papier, etc.): fréquence, responsabilité.
(16) Requêtes de diffusion sélective de l'information: modalités de mise sur pied et d'exploitation.
(17) Listes de contenu contrôlé (listes d'autorités, thésaurus, etc.): nature, responsabilité.
(18) Besoins en sécurité: protection par mot-de-passe, encryption, copies de sécurité, etc.
(19) Matériel informatique (ordinateur et périphériques: imprimante, modem, etc.).
(20) Infrastructure réseau requise (matérielle et logicielle).
(21) Logiciel d'implantation (il s'agira le plus souvent d'un progiciel).
(22) Aménagement physique (incluant mesures de sécurité, si pertinent).
Notes:
- Un champ à valeur ajoutée est un champ dont la détermination du contenu exige un effort important (le plus souvent, intellectuel).
- Une validation est la vérification automatique par le logiciel d'une règle d'écriture.
Établir l'ensemble des choix possibles pour les différents paramètres à considérer est une tâche difficile, qui exige beaucoup de jugement, d'expérience et de créativité. Bien qu'il n'y ait pas de recette miracle, certains éléments sont importants à considérer à cette étape.
Il est bien sûr hors de question de considérer tous les choix possibles pour tous les paramètres les uns après les autres: le nombre de combinaisons possibles serait beaucoup trop grand. Au lieu de cela, on procédera en général comme suit:
a) Identifier les "paramètres imposés", c'est-à-dire ceux pour lesquels une seule réponse est possible, soit en raison des contraintes particulières ou des objectifs à atteindre, soit indirectement, parce qu'ils découlent d'autres paramètres, eux-mêmes imposés.
b) De façon heuristique, et par confrontation de différents scénarios, déterminer les choix possibles pour les paramètres restants. ("Heuristique" veut dire ici que l'on éliminera parfois des avenues a priori possibles, sans évaluation en bonne et due forme, simplement sur la base de l'expérience, de l'intuition ou du bon sens.)
Le modèle de données étant relié de façon tellement intime aux fonctionnalités que peut avoir une base de données, ce paramètre est plus souvent qu'autrement (mais pas toujours) "imposé" par les objectifs à atteindre. C'est donc souvent un des premiers paramètres à être fixés. La nature des autres paramètres à considérer est alors déterminée dès le début de l'étape d'identification des solutions possibles. Le logiciel d'implantation est en général un des derniers paramètres à être déterminés.
Normalement, on devrait arriver à un nombre restreint de solutions possibles, disons au maximum cinq ou six, et de préférence deux ou trois.
Il est normal que deux personnes effectuant la même étude de faisabilité n'arrivent pas nécessairement aux mêmes conclusions: après tout, il s'agit d'un processus de création comportant une part inévitable - et importante! - de subjectivité. Une trop grande dissimilitude entre les différentes études pourrait cependant être le signe d'une faiblesse dans l'une d'elles.
Pourquoi nous nous restreignons au modèle textuel: Le modèle textuel est celui le plus souvent utilisé pour les bases de données documentaires. Cependant, il n'est pas nécessairement le mieux adapté à toutes les bases de données de ce type. Pour pouvoir déterminer quel modèle de données convient le mieux à des objectifs donnés, il faut idéalement connaître tous les modèles de données potentiellement utilisables, c'est-à-dire tous ceux pour lesquels un bon nombre de progiciels sont disponibles sur le marché. C'est la raison pour laquelle une étude de faisabilité pour une base de données documentaire devrait toujours être effectuée par un spécialiste de l'informatique documentaire: celui-ci est familier avec tous les modèles pertinents, et non un seul.
Dans cette étape, les solutions qui ont été identifiées comme possibles à l'étape précédente sont évaluées, de façon à pouvoir y rattacher des coûts et des bénéfices, autant directs qu'indirects. Pour chacune des solutions possibles, le responsable de l'étude de faisabilité essaiera d'établir le mieux possible:
Sur la base de l'évaluation faite à l'étape précédente, une recommandation de solution à retenir est faite. Il est à noter que le critère coûts-bénéfices ne doit pas être appliquer aveuglément. Il se peut que des considérations d'un autre ordre (par exemple, politique; voir [Mercure, 1989]) influencent le choix de la solution recommandée.
Dans des circonstances spéciales, il se peut que plus d'une solution soient présentées. Il faut restreindre au minimum les solutions possibles. Ces solutions doivent être suffisamment précises pour que les gestionnaires eux-mêmes puissent trancher, sans devoir recourir à de l'aide extérieure. Si les solutions proposées ne sont pas assez précises, c'est probablement à cause d'un "manque d'information". Une révision des solutions proposées serait de mise.
La forme que doit prendre une recommandation de solution est bien sûr la liste de tous les paramètres qui définissent cette solution.
Sur la base du rapport de l'étude de faisabilité, et si le bien-fondé d'une base de données documentaire a bel et bien été démontré à la satisfaction des gestionnaires, ceux-ci prennent alors la décision d'aller de l'avant. En général, un budget est attribué au projet à ce moment. Commence alors la phase de conception finale de la base, réalisée par un spécialiste de l'informatique documentaire ou de l'information.
Au cours de cette opération, le dictionnaire des données de la base de données est mis au point. Celui-ci fixe définitivement la structure de la base et ses relations avec le monde réel, compte tenu du logiciel d'implantation faisant partie de la solution retenue. Le dictionnaire des données constituera la référence principale sur la base de données pour toutes les personnes impliquées dans sa gestion ou son utilisation. On peut décider de faire en plus un guide de l'utilisateur plus succinct. Il faut également établir de façon précise et par écrit (par exemple sous forme de manuel) les procédures de gestion de la base.
Une fois le matériel et les logiciels acquis et installés, on peut commencer l'implantation de la base de données. La structure de la base est définie dans le logiciel d'implantation, de même que tous les autres paramètres sous le contrôle du logiciel d'implantation, comme les différents bordereaux, les formats de rapports, et les procédures de validation. Une opération d'entrée initiale de documents est ensuite effectuée, de façon à ce que la base contienne un nombre suffisant de fiches pour pouvoir être fonctionnelle.
On effectue des tests de fonctionnement, de même que la formation des usagers, s'il y a lieu. À ce stade-ci, toute documentation complémentaire au dictionnaire des données doit être complétée (manuel de procédures, guide d'utilisation). Enfin, lorsque les tests de fonctionnement sont concluants, la base est mise en service.
Par la suite, des opérations de saisie rétrospective seront effectuées périodiquement, tel que prévu par l'échéancier d'implantation, jusqu'à ce que le contenu prévu de la base de données soit complètement couvert. La base a alors atteint sa couverture complète, et seules des opérations de mise à jour périodique pour refléter l'évolution du corpus de documents couvert sont nécessaires. La gestion journalière de la base de données (prise de copies de sécurité, production de rapports périodiques, etc.) est effectuée selon les procédures établies précédemment.
Référence:
MERCURE, Gérard. "Le choix d'un logiciel documentaire, une décision technique, administrative ou politique?". Argus, vol. 18, no 1, printemps 1989, pp. 16-24.
Schéma : Le schéma sur la page suivante, réalisé par Christine Dufour, présente graphiquement les différentes étapes dont il est question dans ce texte.