 Copyright © 2006-2021 Yves MARCOUX; last modification of this page:
2021-12-15.
Copyright © 2006-2021 Yves MARCOUX; last modification of this page:
2021-12-15.This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Canada License
Copyright © 2006-2021 Yves MARCOUX; last modification of this page:
2021-12-15.
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Canada
License
Yves MARCOUX - EBSI - Université de Montréal
Please use the RSS wire as a table of contents
Coming up soon (well, you know what I mean…):
- Uninformation (ininformation in French): when you act as you say a lot, but actually say nothing, on purpose.
- Dialogical vs monological (i.e., finite footprint) communication.
- Algorithmic dependencies between phenomena, as opposed to quantitative dependencies.
- Improved version of “Sex, lies, databases, and interfaces.”
- Artificial languages for humans.
- Differential structural semantics.
- Sciences, science, and the Web.
- Blogues à effet de serre.
- Beyond Web 7.0.
Entries below are in descending (i.e., inverse) chronological order
2024-10-06 Sunday ![]()
Je viens de terminer la lecture de La fin des temps, roman de Haruki Murakami, auteur qui m’avait été recommandé par un ancien élève de l’EBSI à l’occasion d’un échange Facebook autour de mon anniversaire, donc début juillet. La lecture s’est étendue sur une si longue période en raison de contingences qui seraient longues à expliquer et dont la plupart n’a aucun intérêt public. J’ai notamment lu en parallèle d’autres livres (dont Le parfum des poires anciennes d’Ewald Arenz).
Ceci n’est pas une critique de l’ouvrage, mais quelques réflexions personnelles dont le volume dépasse un peu ce qui tient facilement dans mon agenda courant.
J’ai beaucoup aimé les univers complètement surréalistes où se passe l’action – ou plutôt, se déroulent les actions. À mi-chemin, cependant, j’ai trouvé qu’il y avait beaucoup de longueurs. Puis, vers la fin, les choses se mettent un peu à débouler et là, j’avais du mal à m’arrêter, car je voulais connaître la fin.
Fin qui m’a déçu. Ce n’est pas celle à laquelle je m’attendais, ni celle que je souhaitais. Il me reste une espèce de tristesse, justement du fait que les personnages (auxquels j’avais eu le temps de m’attacher beaucoup – tous les personnages, sauf peut-être les deux malfrats – vu la durée sur laquelle s’est étendue ma lecture) n’ont pas la destinée que je leur aurais souhaitée. J’espérais en particulier que Murakami trouve une façon de concilier, ou peut-être plus harmoniser, les destinées de l’ombre et de la bibliothécaire de la fin des temps. Mais non, il ne l’a pas fait…
Je trouve aussi que beaucoup de détails présentés au début (pas seulement lors des digressions inutiles que j’ai appelées « longueurs »), comme l’effacement des sons, pour n’en mentionner qu’un, s’avèrent finalement inutiles. J’aurais espéré que, magistralement, l’auteur arrive à mettre en jeu tous ces éléments bizarres (pour ne pas dire extravagants, en tout cas invraisemblables, comme l’existence même des ténébrides) dans une espèce de deus ex machina conférant à tous un apaisement final satisfaisant, autant pour les personnages que pour le lecteur. Même le détail de la congélation, pourtant amené à la toute fin, tombe à plat. Il me semble qu’il y aurait eu là matière à ouverture vers une fin plus riche en potentialités.
Bref, très content d’avoir fait la lecture, mais déçu quand même un peu de l’écriture et passablement de la fin. Et c’est bien dans l’ordre des choses que cette lecture m’ait été recommandée par un ancien de l’EBSI, parce les bibliothécaires et les bibliothèques y jouent un rôle fondamental.
2018-02-05 Monday ![]()
I found a light and simple way to solve the local indexing problem of my XHTML files, that does not involve changing the indexing options at all, thus leaving XHTML files to be indexed with the default “Properties only”.
First note that, for documents that require XSLT processing before publication,
there is no real problem, because the output of the XSLT transformation is named
.html (by the applicable default oXygen transformation scenario),
which is locally indexed correctly (even though it is actually XHTML, but that
doesn’t seem to bother the HTML filter). Thus, that file (sitting just next to the
original .xhtml file on my machine) is indexed properly, and will come
out in searches “instead” of the original XHTML file that is indexed as “Properties
only”.
There remains the case of XHTML files for which no XSLT processing is required
(i.e., which are already “not-too-wild”, in the sense of My
new web publication strategy). For those, I simply name them
.html in the first place, rather than .xhtml . oXygen
makes no fuss and recognizes them as belonging to the correct framework. And they
get indexed correctly. And when the reach the server, they get served, as I want it,
as HTML. Bingo !
This very file, named index.html, is an example.
2017-11-20 Monday ![]()
A quick note on how changing my web publication strategy to XHTML affected my information management locally. Again, this should not have come as a surprise, but it actually did…
In the default indexing options of Windows, XHTML is indexed as “Properties only.” Of course, I want the content to be indexed too. But the only option (without fiddling in the Register) is “Plain text.” Sadly, it turns out that with that option, accented characters are only recognized properly if the file has a BOM. Thus, I need to make sure my local files do have a BOM, since I want them to be content-indexed.
For this, I have two options: either configure the « Encodage du document » option in oXygen to always write a BOM for UTF-8 files, or configure the option to « Conserver » and make sure I insert a BOM in all my files by hand (i.e., with Notepad++). I chose the second option.
The down-side (with either option) is that the W3C validator for XHTML gives a warning that a BOM is present (suggesting to remove it until better supported). I will live with the warning.
2017-11-13 Monday ![]()
I should have realized it earlier, but only a few days ago did it occur to me that having “approximate XHTML” served to clients would prevent W3C validation to succeed. And since I put links to the validators at the end of my pages and have no desire to compromise on that, I had to find a solution. Here is what I found: if the “not-too-wild” XHTML is 100% kosher XHTML (still “not-too-wild,” i.e. avoiding complicated stuff like local subsets and linked XSLT stylesheets), then the W3C validations work perfectly, in spite of the fact that the XHTML is served as HTML. In other words, the W3C validators totally ignore how a file is served, and only look at its content.
So, I just had to make minor changes to my XSLT stylesheet so it outputs 100%
kosher, validating XHTML. With the oXygen transformation scenario naming the output
.html, it gets served (locally and remotely) as HTML, and the
browsers are happy. And me too, because I can copy-paste from them while browsing. I
am talking here about a structural copy-paste, where the HTML structure is carried
over to the application where the paste occurs.
Changes to the XSLT stylesheet were tiny; I think the biggest was to remove
<meta charset="UTF-8" /> from the
stylesheet and just make sure my original XHTML had a <meta
http-equiv="Content-Type" content="charset=UTF-8" /> element (the XML
declaration with encoding is not enough for browsers who get served HTML). Probably
the “hardest” thing was to make sure the XHTML output did not have namespace-prefix
definitions (useless anyway) like
xmlns:h="http://www.w3.org/1999/xhtml". A
exclude-result-prefixes="h" attribute on the root-element of the
stylesheet did the trick.
2017-09-26 Tuesday ![]()
A couple of years ago, I got excited about publishing my web stuff in XHTML, mainly because of the widespread support for “true” XHTML: the one including local declarations (default attribute values, entities, etc.) and links to XSLT stylesheets (XHTML input and XHTML output, for example for a dynamic TOC). I had found out that most browsers would behave correctly with local declarations and XSLT if the XHTML was indeed served as such; in fact, I had found that only some versions of the Windows phone would not behave correctly. Another reason for getting excited was the excellent XHTML support in oXygen, which I had been only using for idiosyncratic XML so far; being able to edit my XHTML stuff with it constituted a way out of XMetal, of which I only have an old unsupported version, and whose latest versions have both become out of price and dropped HTML support. Plus, the “genuine XML” idea in general appealed to me, especially the possibility of processing it with XSLT for other things than web publication.
But then, a few weeks into applying that strategy, I hit some minor problems with both Firefox and Chrome when a TOC was generated with an XSLT stylesheet. The circumvention was easy for Chrome, so I didn’t report the problem, but I did open a bug for Firefox. The reply I got was very discouraging. In essence, their answer was “wont-fix” because XHTML is “deprecated technology.” OK…
I have been wondering for a while what the best course of action would be. Today, I
decided I would stick to XHTML, but apply locally (“publisher-side”) any
transformation I may want, publish the result as it comes out (thus, as XHTML, but
not “too wild”), and manage to have it served as HTML. My tests today
seem to indicate that major browsers handle that (not-too-wild XHTML served as HTML)
satisfactorily well. I should note in extenso what I mean by
“not-too-wild”: no local subset, no XSLT link, UTF-8 encoding without
BOM, no XML declaration (the encoding pseudo-attribute is ignored
anyway by browsers), and
<meta charset="UTF-8" /> in the header. Two
important points:
<html xmlns="http://www.w3.org/1999/xhtml">
<meta content="width=device-width, initial-scale=1.0" name="viewport" />
The way I manage to have such pages served as HTML (text/html) is to
have the result saved with the extension .html. My non-exhaustive tests
so far indicate it works with all browsers, locally and remotely.
I must say one huge nuisance that serving HTML gets rid of, is that when browsers
get served an XHTML document as such (application/xhtml+xml), you
can’t copy structured content into other apps (Word, for instance). Whatever
gets put on the clipboard lands as text in the other app, not as HTML (perhaps
simply because it is put as text on the clipboard by the browsers). So,
this is a big relief.
Now, there is a small problem with serving (what is basically) XHTML as HTML: you
must not have an empty <style /> element; in fact, any
element that can have content in HTML must not be empty (though I suspect
empty <p />s wouldn’t cause much trouble). Why?
Because the self-closing tag gets interpreted by the browsers as an start-tag, so it
keeps looking for the matching end-tag forever (and, in the case of
style, does not display anything). I use to keep an empty
<style /> element in my documents, just to have handy a
reminder of the exact attribute needed. I solved the problem by changing
<style type="text/css" /> to
<style type="text/css">/* Not empty
*/</style> in my “empty” XHTML template file.
Thus, in the XHTML framework that I use in oXygen (it is an extension of the XHTML
framework included in oXygen), I added an XSLT transformation (which I declared
“default”) that is a modified version of the TDM.xsl that I
used until now to add a TOC. What I did is make the inclusion of the TOC conditional
on the presence of a <?TDM ?> PI anywhere in the document.
That PI also serves as a place-holder for where you want to have the TOC (the TOC
will end with an <hr />, so you should place the PI after an
<hr /> that is already there); it must be a direct child
of body (if it is not, the TOC will be placed at the end of the body after
everything else, which is not very interesting).
The reason I wanted TOC-generation to be optional is to have a single XSLT to take
care of all my published XHTML documents, resolving local entities if any + in
general taking care of the local subset (which could do quite elaborate things, like
adding or redefining attributes or elements), in addition to generating a TOC if
desired. With this stylesheet, handling of the local subset always occurs, and
TOC-generation occurs only if asked for via the inclusion of a
<?TDM ?> PI.
Two obvious improvements would be to make the thing bilingual, i.e., accept also
<?TOC ?>, and insert Table of contents instead of
Table des matières (maybe deciding based on the
xml:lang of the document), and paramatrize the depth of the TOC.
The XSLT stylesheet is at "C:\Program Files\Oxygen XML Editor
18\frameworks\xhtml\xslt\TDM.xsl". The transformation scenario is
defined (under Options / Association de type de document / XHTML - Extension YM /
Transformation / XML transformation with XSLT) as:
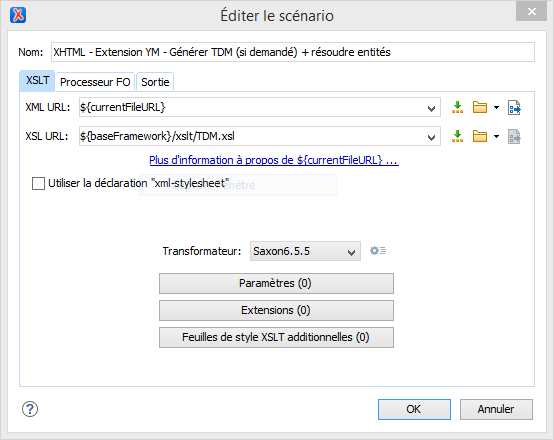
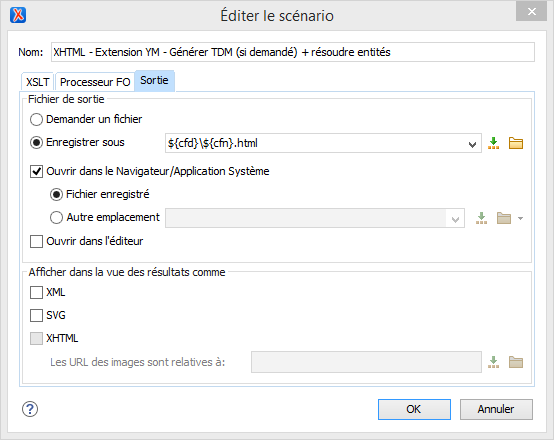
So my authoring process is to author everything in true XHTML (i.e., possibly with
non-empty local subset), with .xhtml extension, include a
<?TDM ?> if I want a TOC, then, before publishing, run
this scenario (since it is default, just pushing the “transform” button
does it), which creates the equivalent .html file containing the tamed
XHTML (to be eventually served as HTML).
Note the following harmless side-effect to running the
scenario, even when no TOC is asked for: all headers h2 to
h6 that do not already have an id attribute are given
one with a unique generated value. It would be easy to modify the stylesheet not to
do it when no TOC is added, but I see no good reason to expend the effort.
Thus, I will end up with both a .xhtml and a .html file
published in the same directory. For that strategy to work, I must make all
links must point to the
.html
files. Also, index.html must have priority over
index.xhtml as default document for IIS. For this last point, I had
to put a <clear /> at the beginning of
<files> in web.config, followed by the appropriate
<add />s (including one for .html) in the
desired order (no need for any <remove />s after the
<clear />).
A final note: in XHTML files for which I want a TOC, there was until now a link to the TDM stylesheet. That link is now unnecessary; it is, in a sense, “replaced” by the TDM PI. However, I do not see any good reason to systematically remove it from all files, since it does not harm.
So, that’s what I’ll do for a while, and see how it fares!
Another advantage to have the XSLT transform performed “publisher-side” is that I need not restrict myself to XSLT 1.0, but can use 2.0 and even 3.0 (which oXygen both supports)!
2017-04-18 Tuesday ![]()
Recently, I stumbled unto an article I had written in 2005, while I was trying to orient myself in the wonderful world of document semantics. As is usual when I read old stuff of mine, I found it very good, though it had been rejected by a well-known document engineering conference. I thought perhaps I should resurrect it, so here it is.
As is the case for this other article, published, also in 2005, in the Revue maghrébine de documentation, I find that the main ideas underlying the then-yet-to-come-into-being IS framework are already percievable.
2015-04-15 Wednesday ![]()
À la une du Métro ce matin : « Celui-ci commencera à être déployer en 2016. » Non, mais où s’en va le monde, je vous le demande? Ah, là là !
2015-04-15 Wednesday ![]()
Trouvez-vous, vous aussi, qu’il y a une recrudescence dans l’espace public, du mot « docteur » pour parler des médecins? Évidemment, l’émission de Radio-Canada « Les docteurs » n’a sûrement pas aidé, mais je trouve que la vague actuelle ne peut s’expliquer exclusivement par ça.
En tant que docteur non médecin, cette tendance me met mal à l’aise, car j’ai une espèce de réticence instinctive à parler du médecin comme du « docteur ». Pour moi, « aller chez le docteur », ça fait un peu manque d’éducation, comme si on ne savait pas qu’il peut y avoir des docteurs dans d’autres disciplines que la médecine.
Peut-être est-ce simplement une statégie des communicateurs de se mettre à un certain niveau de langage pour les auditeurs? Je ne suggère pas que les communicateurs pensent réellement que les auditeurs ne comprennent pas la différence entre docteur et médecin, mais je crois qu’ils utilisent le mot « docteur » pour son pathos, son effet évocateur.
Un exemple? Un titre, à la une du Métro ce matin : « Anecdotes d’un docteur-poète »; pourtant, dans le paragraphe qui suit, on parle bel et bien de médecin. Pourquoi, donc, le titre n’est-il pas « Anecdotes d’un médecin-poète »? Est-ce que « docteur » fait plus accessible, voire même évocateur de sécurité, celle de l’enfance, où on allait « chez le docteur » avec maman pour faire guérir son bobo? Je suppose que oui.
En tout cas, pour moi, ce n’est pas anodin, ça témoigne de quelque chose. Quelque chose d’amusant à essayer de comprendre.
2014-04-07 Monday ![]()
Non!!!! Pas libéral majoritaire! Anything but libéral majoritaire! Môman... Qu’est-ce qui va nous arriver à nous québécois? Je n’en reviens pas; il n’y a donc aucun espoir? Quand nous rendrons-nous compte que cette gang de pleins aux as et corrompus à l’os se foutent complètement de notre yeule, une fois qu’ils ont eu notre vote? Probablement jamais, que conclure d’autre aujourd’hui? Peut-être que Marc Arcand est notre seul espoir? Consolons-nous avec un peu d’humour… Notez que lui non plus n’a pas tellement la cote, par les temps qui courent…
2013-05-17 Friday ![]()
L’École d’été en architecture de l’information se tiendra encore cette année à l’EBSI du 10 au 21 juin 2013 :
L’École est ouverte tant aux étudiants de la MSI de l’EBSI qu’aux professionnels. Voir les modalités d’inscription.
Consultez le site de l’école d’été ou écrivez-moi pour en savoir plus !
Yves Marcoux
Professeur
EBSI – Université de
Montréal
L’EBSI remercie chaleureusement ses partenaires
Irosoft | Experts en technologie documentaire et
INM.com
pour leur soutien financier dans la
préparation de cet événement
2013-01-16 Wednesday ![]()
Mot rédigé à l’occasion du départ de Lucie Carmel, responsable des laboratoires d’informatique documentaire de l’EBSI.
Chère Lucie,
La première image qui me vient à l’esprit en pensant à toi est celle d’une bouée de sauvetage; celle à laquelle je me suis accroché lorsque j’ai plongé (en 1991 !) dans l’univers de l’informatique documentaire. Par tes connaissances dans ce domaine, certes, mais aussi par ton profil scientifique en général, tu représentais une des rares personnes (peut-être la personne) à l’EBSI avec lesquelles je partageais un vocabulaire et une sensibilité disciplinaire. Pendant de nombreuses années, c’est par ton entremise que j’ai pu me tenir au fait des développements dans le domaine.
Ton attitude de service, appuyée sur une rigueur et un professionnalisme insurpassés, j’en ai bien sûr bénéficié directement, mais j’ai également vu les promotions d’étudiants de l’EBSI en profiter, année après année. Autant par l’exemple que par des échanges directs sur le sujet, tu m’as énormément aidé à réaliser toute l’importance de « l’utilisateur », qu’il soit étudiant, lecteur ou autre.
Un immense merci, donc, pour toutes ces années de service, de soutien (technologique et moral !), de complicité et d’inspiration.
Une autre image à laquelle je t’associe, et que je garderai toujours avec sourire et émotion, est celle des longues discussions philosophico-disciplinaires que l’on avait occasionnellement, lorsque le hasard faisait que, pour toi comme pour moi, la fin de l’après-midi (voire le début de soirée !) à l’EBSI s’étirait.
Je te souhaite une chose certaine : du succès dans tes nouvelles fonctions. Comme tu ne vas pas très loin, j’ai la conviction que nous continuerons à bénéficier de tes grandes qualités professionnelles, même si ce sera maintenant par personnes, systèmes ou politiques interposés !
Et, comme tu ne vas pas très loin, j’espère que nous aurons encore de nombreuses occasions de rencontres, discussions et – pourquoi pas ? – collaborations !
Merci !
Yves
2013-01-14 Monday ![]()
I just installed HandBrake 0.9.8 (an open-source, GPL-licensed, multiplatform, multithreaded video transcoder), and it is a pure joy ! What a rare fact that you should install a piece of software (free software or not) and that it would work as expected immediately ! It seems to accept all the popular video formats (it does accept all mine) and does not make any fuss about details that come out of nowhere. A tiny example of how carefully the product has been developed: in Windows Explorer, if you want to keep note of the path to some file (for later opening it with another program), you Shift+RightClick on the file, then select “Copy as path”. This places the path to the file (as text) on the clipboard. Because there can be spaces or other special characters in the path, it is surrounded by double-quotes on the clipboard. Many (if not most) programs will not accept the quotes in their file-picker, so that you have to remove both of them (at opposite ends of the entry box!) after copying the path. HandBrake behaves like a helpful citizen, and silently ignores the double-quotes, as all users will agree is the most useful thing to do. The interface is simply 100% natural.
Considering how picky, fussy, sissy, and critical I am about software (and designed things in general), please consider this rare rave as extremely meaningful.
BTW, I found HandBrake by searching the The Free Software Directory for "mp4 conversion".
2013-01-03 Thursday ![]()
Look at the signs along roads and corridors. Look at the words on them, or rather, at the expressions. Most of them are nouns or noun phrases. When there are verbs, they are usually part of a noun phrase. Same for adjectives, though now and then, you see a self-standing one. But verbs! Where are they? I’ll tell you: you see them mostly on advertisement signs and they are head of an infinitive or imperative phrase (notable exception: PULL and PUSH on doors). Someone wants you to do something (usually pay for something or at least get interested in it). But in real human conversations, self-standing noun phrases, infinitive, and imperative phrases are rather infrequent. Designers and architects are talking to us through their artefacts (the de Souza view). What kind of language are they speaking?
My view is that the verbs lie in geometric relationships. Geometric relationships among things are what allows us to communicate with designers and architects in a normal conversational style, that includes subject-verb-complement sentences; not always, but at least sometimes.
2012-12-16 Wednesday ![]()
… belle semaine en perspective !
2012-05-22 Tuesday ![]()
Au secours ! Mon premier ministre est un schizophrène complètement déconnecté de la réalité ! Il a des yeux, mais ne voit pas. Il a des oreilles, mais n'entend pas. Ou plutôt, il n'entend que des voix intérieures qui lui répètent inlassablement qu'il a raison.
Monsieur Charest, vous avez déjà attendu trop longtemps pour avoir quelque espoir de vous en tirer indemne. Donc, malheureusement pour vous, vous allez devoir perdre la face. Et, bien sûr, le discrédit dans lequel vous êtes maintenant tombé ne s'estompera pas. Vous aurez donc à jamais la réputation d'un homme qui a provoqué et laissé pourrir une des pires crises socio-économiques de l'histoire de votre pays, le Canada. Mais, soyons positifs: je crois que vous avez encore une chance avec la pitié.
Voici ma suggestion: et si, contre toute attente, vous démontriez subitement une parcelle d'humanité? Si vous vous laissiez émouvoir par la belle solidarité et les aspirations profondes dont fait preuve en ce moment notre formidable jeunesse? Vous perdriez bien sûr la face, là n'est pas la question, puisque, je l'ai déjà dit, le mal est fait. Mais si vous la perdiez avec un peu d'humilité, en reconnaissant sincèrement vos torts et en posant immédiatement les actions réparatrices nécessaires (vous les connaissez très bien, et elles sont tout à fait à votre portée), oui, je pense qu'il y a quelque chance que certains québécois vous fassent la grâce d'un peu de leur pitié. C'est le mieux que vous puissiez espérer. Par ailleurs, ça nous redonnerait peut-être enfin l'impression de vivre dans une société habitée par des humains, plutôt que dans un mauvais film d'anticipation sociale à catastrophe mettant en vedette des zombies dénués de tout sentiment.
2012-05-18 Friday ![]()
I have been (re)reading recently writings by Don Norman and Clarisse de Souza. Most of it is a joy and much enlightment. But I feel their insights, while excellent for deconstructing existing phenomena, and to a certain extent useful for constructing new ones, still leave a lot to be desired when it comes to a coherent approach / model / method for design. Now, Norman is interested in the design of anything, not just information objects. That is a big difference with me; I only want to account for information objects. De Souza is more focused on information objects, so one could hope to derive a coherent approach / model / method from her way of looking at things. I think de Souza herself would object to my idea of what I call “coherent approach / model / method” (I should adopt an acronym for that, let's say CAMM). That's because she insists her theory cannot be used predictively. I don't agree, I think she is being too modest. I do believe her theory can be used predictively. Of course, with no measure of probability of success (and maybe that's why she refuses the label), but still, with high probability of success, even if such probability cannot be asserted beforehand. Anyway, that's my definition of “predictively”, so I will keep saying that de Souza's methods (SEM and CIM, essentially) can be used in that way. And likewise for intertextual semantics (IS).
I should say we have made a lot of progress (with Élias) while writing a short paper for an upcoming conference in the line of building a method around IS. Peculiar as it may sound, it is actually a method for both deconstruction and construction (construction is a nice name in the dyad “deconstruction-construction”, but it's really design we mean here). It's actually based on the following principle (which I consider to be simply an observation): construction (design) of an object can (and perhaps should) be considered as an iterative process involving very tight cycles of deconstruction / reconstruction. Much as in writing: the author will constantly reread the last bits she has written and make minute adjustments. Sometimes the cycles are longer: she will reread a whole section, or even the whole work; but it is all on a microscopic time level. (Mind you, if the finality of the text warrants it, she will eventually go to the “user testing” stage, which will involve rereading on a more macroscopic time level: she will have someone else read and comment the text, or she may herself take the guise of another person by waiting long enough to reread her own work... long enough that she actually literally becomes another person.) In the microscopic time level cycles, she just does not have access to user testing (for many reasons), yet, she must produce hypotheses about what will work. I claim this does not need to be entirely blindly; heuristics, based on a CAMM, can help here.
So the basis of the method we are envisaging is to consider object design as a form of writing. And, of course, that is exactly the view IS is geared to support.
Enough said about the desirability of a CAMM for the design of IOs and what we are trying to do in this line. The purpose of this entry here is to enumerate a few of the parameters you need to question yourself about when you enter the task of designing an information object (BTW, I shamelessly and bluntly use “information object” because I have recently seen it used by Ingwersen and Järvelin without any fuss, convolution, or apology).
2011-04-25 Monday ![]()

Yé ! 8^(
2011-02-16 Wednesday ![]()
Bonjour,
Ce message est rédigé en pensant à Philippe Schnobb, mais pourrait s'adresser à toute personne impliquée dans la gestion des médias sociaux à la SRC.
À l'occasion du superbowl, j'ai visionné quelques publicités faites pour l'occasion. Dans un des clips de PepsiMAX, j'ai remarqué une caractéristique que je trouve extrêmement intéressante.
Au lieu de donner l'adresse de leur page Facebook directement, elle était donnée via une indirection, comme ceci:
PepsiMAX.com/facebook
Évidemment, comme on peut s'y attendre, cette adresse renvoie à:
www.facebook.com/PepsiMax
Quelle différence, direz-vous? À mon avis, toute la différence. Donner l'adresse directement, comme il est fait habituellement (notamment à la SRC), me semble porter le "métamessage" qu'on se livre pieds et poings liés à Facebook (une entité commerciale), autant techniquement que socialement et idéologiquement. Le faire via une indirection lance le métamessage que, même si on adopte pleinement et avec enthousiasme la réalité des médias sociaux, on se garde quand même une petite distance, peut-être même un certain esprit critique.
Qu'en pensez-vous? Pourquoi pas un
radio-canada.ca/tj18h/facebook ?
Merci d'avoir lu au-delà de 140 caractères!
Cordialement,
---------------------- Yves MARCOUX, Ph.D., ift.a., professeur
agrege
------------------------------ <GRDS> - EBSI - Universite de
Montreal
----------------------------
<http://mapageweb.umontreal.ca/marcoux/>
---------------------------------
(514) 343-7750 / FAX (514) 343-5753
2009-12-05 Saturday ![]()
Surprise ! Du français. Je me dis que, comme cet espace ne sert de toutes façons pas (simplement parce que je n'ai rien à dire en public), pourquoi ne pas l'utiliser pour des notes qui, qui sait, pourraient en intéresser certains.
Souvenirs réveillés: discussions ontologiques (Maisonnée & Temps perdu).
De la Maisonnée (1 avril 2009), en fait, je ne me rappele plus ce qu'on s'est rappelé. Par contre, je viens de miraculeusement retrouver un compte-rendu, rédigé le lendemain. Et aussi un autre compte-rendu, de même que des entrées du document « marcoux-fondements » (à revisiter régulièrement !) qui ressemblent un peu à des comptes-rendus. Le fait d'avoir retrouvé ces trucs me convainc de toujours rédiger des CR et de les mettre à un endroit visible (comme ici, mais ça pourrait changer), plutôt que de les rédiger comme courriels.
Je reproduis tout ça ici (en essayant de faire rétrospectivement un CR de la rencontre du Temps perdu), en ordre chronologique inverse:
2009-05-25 « Fondements »
En faisant l'expertise Adonis, je découvre que la norme OAIS, surtout autour de 4.2.1.3.1 Representation Information Types et la section suivante, présente une vision de l'intelligibilité des artéfacts très semblable à celle de la SI... C'est vraiment frappant; notamment, ça parle de “Designated Community” et du fait qu'un programme interprétatif d'un format n'en constitue pas une description adéquate ! À mentionner absolument comme exemple de points de vue voisins. Un autre est les cartes conceptuelles qui, sous leur apparence d'outils entièrement graphiques, sont en fait un mécanisme extrêmement simple de génération de texte.
2009-05-16 Temps perdu
(compte-rendu reconstitué rétrospectivement le 2009-12-05) On établit qu'il n'y a pas moyen de distinguer objets et événements par l'existence de propriétés qui n'auraient de sens que pour l'un. Alors, on a suggéré qu'il s'agit en fait de deux « genres » d'une entité de plus haut niveau, qu'on pourrait justement appeler « entité ». Et, préalablement, on a établi que l'un comme l'autre (et en fait probablement n'importe quelle « entité ») n'existe dans le discours humain qu'en tant que construction sociale / conventionnelle (et donc, négociée).
Je ne sais pas si on l'avait discuté au TP, mais je me souviens de m'être préalablement convaincu que les objets concrets ne sont aucunement plus faciles à identifier ou délimiter ou désigner que les objets abstraits. Je n'ai donc aucune difficulté avec une ontologie dans laquelle les objets (concrets comme abstraits) sont amalgamés avec des événements (qui ne peuvent être qu'abstraits).
2009-04-01 Maisonnée
Deux points importants ressortent de la discussion:
1- Quand vient le temps d'appliquer l'IS, i.e. d'écrire une IS spécifique pour un certain type d'objets spécifique, le modélisateur / architecte n'a d'autre choix que de s'instaurer en "arbitre" pour décider des "mots" ou "expressions" qui peuvent être utilisés avec une forte probabilité d'être compris de façon assez uniforme par la communauté cible.
En fait, en retrospective, cette idée me fait penser à un passage de JASIST2009: "In designing a rendition, a designer must first choose one or more modality, then signifiers, to convey their “message.” They must do this based on their own comprehension of how signifiers operate in the sense-making process for the community of users they have in mind. Such a comprehension can stem from introspection, intuition, personal experience, or empirical experimentation results."
2- Une autre idée est que la métaphore de la chenille (concept flou au sein d'une communauté) devenant papillon (concept bien établi et ayant acquis une valeur symbolique, i.e. dépassant sa signification réelle) est peut-être plus près de la réalité qu'on ne le croit, en ce sens que le passage d'une idée floue et polysémique à une idée fortement consensuelle tient peut-être plus de la métamorphose ou du saut quantique que de l'évolution graduelle. Si c'est le cas, ça pourrait être une chose à garder en tête pour les architectes; en fait, ça pourrait à la limite simplifier la tâche de séparer les expressions galvaudées (à éviter) de celles sémantiquement très focussées (au sein, bien sûr, le collectivité visée): distinguer une chenille d'un papillon est plus facile que de distinguer un jeune papillon d'un vieux papillon.
3- (Oui, je sais, j'avais dit 2.) Élias fait part d'une réflexion récente à l'effet que la tâche de designer une rendition ne se résume pas à reproduire l'IS d'un moule; ça peut demander une reformulation (recasting) radicale de l'IS, dans un contexte de discours potentiellement très loin de celui du moule ou des IBOs formels gérés par le système. Yves est en partie d'accord, mais il a du mal à lâcher l'idée que l'IS est fondamentalement "ce que l'objet veut dire" et que donc, elle devrait servir de guide, ou en tout cas de trame ou être en filigrane, dans le design des renditions.
2009-03-05 EBSI
M: modeller
A: auteur
R: rendition designer
U: lecteur (utilisateur)ER fait remarquer que les phrases à trous peuvent être interprétées comme invitant à l'action, et que la nature de cette action va dépendre de quelle conversation exactement est médiée par la phrase (p.ex., M -> A ou M -> R).
YM demeure convaincu (jusqu'à preuve du contraire) que la forme la plus générale, et qui convient à toutes les conversations est celle complètement dépliée, formulée à l'intention de U.
ER relate une conversation avec une prof d'infocom de Laval: selon elle, elle ne voit pas de relation dans le fait qu'un retour chariot sépare géométriquement deux phrases ou blocs, mais plutôt une seule opération.
YM y voit au contraire clairement une relation, qui (postulat) pourrait être explicitée par une phrase à trous (2 trous), que l'on instancie en plaçant le premier bloc dans le premier trou et le deuxième dans le deuxième.
YM souligne qu'il y a 2 sortes de géométrisations: (1) celles "tolérées" dans le language des intended interpretations (techniquement, le range de la fonction sémantique) et (2) celles que l'on retouve couramment dans les renditions (et les interfaces et artéfacts classiques) et qui, dans le framework IS, doivent nécessairement être traduites en texte (modulo qu'il peut demeurer une certaine géométrisation du premier type).
Extraits des « fondements »
2008-02-22 Hypothèses d'articles à venir: 1- génèse de la SI, dont le texte géométrisé chez Mallarmé (le Coup de dés); 2- document théorique qui décrit où on en est avec la théorie; 3- Un reality-check (RSFA, Atom, SKOS, site Web St-Michael ?); 4- Un article sur l'utilisation d'une forme de transclusion pour attaquer le problème de parcimonie / redondance inhérent à la SI. Pour l'argument de parcimonie, peut-être invoquer la transclusion de Ted Nelson <http://en.wikipedia.org/wiki/Transclusion>.
2008-02-19 Demain, je rencontre Denys Gagnon pour discuter du « Coup de dés » de Stéphane Mallarmé. Ce poème m'intéresse car il incarne une forme de texte géométrisé. Je veux essayer de comprendre quel ajout ou augmentation Mallarmé considérait pouvoir accomplir par rapport au texte « normal » avec un tel « genre » [rép.: la mise en page est une mise en scène]. Sa Préface m'intéresse aussi parce qu'elle illustre la conception d'un auteur sur ce qu'il faut dire pour introduire un nouveau genre non encore établi [2 destinataires; l'un comme l'autre devrait oublier la Préface]. Notes pour la rencontre:
- La préface est en fait un « méta » de classe, puisque M le voit comme le premier artéfact d'un genre à venir, non? Noter que ce « méta » est en « texte normal ».
- « Cette Note » = la préface elle-même?
- Qu'est-ce qu'il considère essentiel de dire au Lecteur « ingénu », et qu'il n'a pas besoin de dire au Lecteur « habile »?
- « Seules certaines directions très hardies... » Il semble suggérer qu'il aurait pu faire plus (dans le poème ou la préface?), mais qu'il ne lui appartient pas de trop (rompre?) avec la tradition: quel est ce « plus » qu'il aurait pu faire?
- Quand il parle de la musique: « On en retrouve... »; est-ce que ça ne devrait pas être « on y retrouve »?
- La dernière phrase à partir de « tandis que »: je ne comprends pas la construction... notamment « que ne reste aucune raison... »; veut-il dire « qu'il ne reste aucune raison... »
- Est-ce que ce « genre » a eu des suites? Est-ce qu'il porte d'ailleurs un nom, ou s'agit-il d'un cas unique? Est-ce que M croyait vraiment que ça deviendrait un genre qui serait porté ensuite par d'autres?
- Les dates de M sont 1842–1898; Le Coup de dés lui-même est daté de 1897.
2007-12-07 Ne pas oublier d'explorer mon idée d'utiliser le « texte géométrisé » comme champ sémantique (i.e. champ de la fonction sémantique) comme généralisation de la sémantique intertextuelle.
2007-11-29 Concernant l'apposition, deux choses: d'abord, j'ai fait une recommandation d'achat d'un livre sur ce sujet (en anglais) (je pense que My Loan va le commander). Par ailleurs, je note qu'une pratique courante au téléjournal de Radio-Canada consiste à utiliser l'apposition pour annoncer le type de traitement d'un topo et le nom du journaliste/reporter qui le fait. Par exemple: "Analyse, Christian Latreille", ou encore "Bilan d'une rencontre qui a mal tourné, Emmanuelle Latraverse". Un fait à noter: on dirait que depuis quelques mois, cette pratique s'est instituée en "signature téléjournalistique radio-canadienne", pratiquement en micro-genre, qui en tant que tel, se développe dans le temps. Ainsi, le premier membre de l'apposition devient de plus en plus long (comme dans mon second exemple ci-dessus). Un cas plutôt extrême serait qqchose comme "Synthèse d'une commission d'enquête qui a réveillé bien des passions, Guy Gendron". J'essaierai de relever un cas réel de ce genre et le noter ici.
2007-03-11 Notes de moi transcrites d'un papier (je crois en préparation de mon séminaire à la Sorbonne, qui a dû être annulé pour maladie): From ethics to technique / A computer program seen as a resolved hyper-sentence / Operator overload, code obfuscation as a case of lying.
2006-11-01 Lors d'une récente conversation avec Élias, je mentionne une analogie entre ce que je propose pour la mise sur pied de systèmes d'information et le monde la construction: c'est peut-être inévitable de botcher certaines tâches, mais essayons donc de botcher la peinture et la décoration, plutôt que de botcher les fondations. En se concentrant sur la vision informationnelle (donc, NL) des systèmes, on s'assure de ne pas botcher les fondations; on pourra toujours botcher le cosmétique et l'esthétique, mais je prédis que ce botchage sera énormément moins dommageable si l'aspect informationnel a été correctement et suffisamment traité.
Compte-rendu proprement dit du 2009-12-04:
La discussion porte sur le concept de « méta », que j'ai envie de formaliser quelque peu depuis une couple de mois.
D'abord, j'ai l'habitude de distinguer méta-donnée en tant que « donnée sur une donnée » et donnée tout court en tant que « donnée sur qqchose d'autre qu'une donnée ». ER fait remarquer que ça contredit un peu l'ontologie établie au Temps perdu, selon laquelle il n'y a pas de différence entre objet et événement. Ainsi, même si le qqchose d'autre qu'une donnée est un événement (alors que la donnée est bien sûr un objet (abstrait)), on est toujours en situation que la donnée est à propos d'une entité de même nature ontologique. (Note: il pourrait tout de même y avoir a priori des cas d'entité n'ayant aucun statut méta la liant à une autre entité; voir 2 parag plus bas.)
YM répond deux choses: d'abord, il ne tient pas du tout mordicus à la distinction donnée-métadonnée. Ensuite, on peut réconcilier les deux points de vue en recourant (comme on l'a fait pour distinguer pragmatiquement objet et événement) aux concepts de genres et sous-genres. On parlerait alors de métadonnée dans le cas où une entité du sous-genre donnée est placée en statut méta par rapport à une entité du même sous-genre.
Soyons donc rigoureux, et adoptons notre propre ontologie: nous n'avons donc que des entités. Deux questions: comment formaliser le statut méta d'une entité par rapport à une autre et une entité peut-elle n'être en relation méta avec aucune autre entité? Autrement dit, être complètement « isolée »? Encore: la relation méta est-elle bidirectionnelle? Porte-t-elle plus naturellement un autre nom dans l'autre direction?
Une note avant de continuer: le point de vue linguistique sur les artéfacts communicationnels ne considère qu'une géométrisation du texte (suite des mots) linéaire et sans trou (s'il y a un mot en position 2 et un en 4, alors il y en a un en 3). Des règles (prescriptives ou conventionnelles) associent un sens aux relations (positionnements relatifs) géométriques entre les mots. Le sens de ces relations combiné au sens intrinsèque des mots permet la production de sens plus sophistiqués (ex: le chat dort: nom collé à verbe dans cet ordre veut dire relation sujet-verbe; l'artéfact complet veut donc dire que le chat dort).
Mon idée, encore imprécise est qu'il y a relation méta lorsqu'un positionnement géométrique relatif (PGR) entre deux artéfacts est utilisé pour véhiculer un sens, mais qu'il n'est pas prévu que ce PGR soit décodé (ou interprété) selon les règles usuelles linguistiques (ou en tout cas, de la langue courante). Évidemment, lorsque le PGR est non linéaire (par exemple, s'il est 2D ou arborescent), alors clairement, les règles usuelles linguistiques ne peuvent pas s'appliquer (puisqu'elles n'exploitent que le linéaire), mais je prétends que même lorsque le PGR est linéaire, le décodage prévu est parfois non linguistique. (Évidemment, un exemple aiderait, et je vais essayer d'en donner un sous peu.)
Je crois que certaines règles stylistiques (manual of styles, protocoles divers de rédaction) sont des exemples qui résultent en des artéfacts géométrisés où les PGR sont à interpréter selon des règles propres au code utilisé, et non à la langue générale. Les règles conventionnelles de formatage des références bibliographiques, par exemple, utilisent à fond l'apposition, mais du coup, fournissent des règles particulières pour son décodage (e.g.: le premier élément est l'auteur, le dernier l'année de publication, etc.). D'autres règles stylistiques utilisent un PGR 2D: par exemple, comment disposer les titres relativement au corps du texte pour une plus grande clarté, etc.
Ce que je trouve vraiment flyé, dans l'exemple de la bibliographie, c'est que les règles de positionnement sont exclusivement positionnelles, et non des règles de PGR entre des valeurs et des intitulés… Alors, où est le statut méta, là-dedans? Entre quoi et quoi? Serait-ce entre la référence globalement et la définition du format?
En tout cas, pour ne pas l'oublier, l'exemple canonique de relation méta que j'avais en tête est celui d'un intitulé et d'une valeur séparés par un « : ». Mais l'exemple que je donnerai exploite diverses techniques de PGR; il s'agit d'une zone d'identification d'un étudiant:

On a du positionnement du méta au-dessus, en-dessous et à gauche. Dans un cas (inscrit en), on s'attend que le PGR avec ce qui suit soit interprété linguistiquement. Notez, incidemment, l'absence totale de « : ». Mais, bon, on pourrait facilement imaginer qu'il y en ait, et ça demeurerait bien sûr compréhensible.
2009-07-02 Thursday ![]()
I truly enjoyed reading: “Poke moi, poke toi - Notre éditrice débarque sur Facebook” by Martine Desjardins <http://nightlifemagazine.ca/magazine/view/2014> (original link broken, archive courtesy of wayback machine). I just loved the non-conclusive, non-rethorical tone of the article, because it is as conclusive and rethorical as one can get on the topic. What else can you say about such an absurd phenomenon as Facebook? This article gives a remarkably complete account of Facebook in 10 paragraphs. One more would be one too many. Martine Desjardins perfectly synthesized and expressed my “thoughts” about Facebook.
2009-02-16 Monday ![]()
The movements we see these days around disciplines: how to combine them in the most creative way (bidisciplinarity, pluridisciplinarity, multidisciplinarity, transdisciplinarity, crossdisciplinarity, etc.) remind me of what happened with tonality in the 19th century. You know how it all ended up? Schönberg, Second Vienna school, atonality (dodecaphonism: all 12 degrees of the semi-tone scale having equal value). The explosion of tonality.
I am myself a proponent of adisciplinarity (latin “a”, or “ab”, for “absence of”). I think disciplines are more often than not used as a shield by so-called researchers to protect themselves either from critic or from the need to question their theoretical and epistemological foundations. Don't you find it strange that the western world has converged towards an almost unique denomination for third cycle advanced studies, Ph.D., but that it shouldn't mean anything anymore? I think disciplines are a thing of the past, a necessary categorization of thought activities, needed in the pre-networked world, but not anymore.
I don't mean disciplines should be replaced by polydisciplinarity, or heterodisciplinarity, or call-it-as-you-wish. Adisciplinarity is the way to go: everything considered at face value for its potential benefits to society, regardless of how well or badly it fits in any kind of predefined scheme of analyzing or doing things.
2009-02-06 Friday ![]()
I thought further about first-time users, and realize there is a danger. It can be profitable to encourage the impression, among users, that being a first-time user must be hard. In that way, users might be more inclined to stick to whatever they know rather than go try something else, just to save themselves the trouble of a becoming a first-time user again. It would be a way to avoid having to get better in order to keep your users. You scare them about changing. In fact, this is as old as commerce, I guess. At any rate, it has been quite a common strategy in technology marketing, I would say in the 70's and 80's. However, with growing user awareness and consciousness, it revealed itself to be bad strategy in the long run.
Hopefully, there will be enough first-time-user-friendly offerings out there that users will refuse to cope with bad ones, and trying to keep them by leveraging fear will turn out to be bad strategy. I think (and hope) simple darwinian selection will make that happen.
2009-02-05 Thursday ![]()
The reason is simple: there are more first-time uses now than before. Why? Globalization, Internet, the Web. Fundamentally related to “long-tail economics,” I think (products and services reaching previously unreachable markets). There are more offerings to any particular individual than before, for just about any type of service. Take for example libraries. I have access to many, many more libraries than my grand-mother had access to. She probably had access to two or three libraries; I have access to at least two or three thousand.
That doesn't mean, though, that I will become a user in that many libraries. So, how am I going to choose (leaving out any coertion factor)? Well, anyone who can come up with a way of becoming a user without first being a first-time user has a brilliant future. But in fact, the answer can only be: by being a first-time user! Aha! This is why we must treat them as kings! There is so much choice, that the places we feel right at home are where we'll choose to become simply “users.”
That doesn't mean that a first-time experience has to be exactly similar to all the following ones. Not at all; it's only natural that there be a progression, also in the efficiency and (yes!) pleasure of the experience. But the very first experience has to be pleasurable, at least satisfying, from an efficiency point of view. The first-time user must come out of the interaction with the feeling that they have not lost their time, that they have not invested their precious time in the gratification of other people who care only about their own success.
For that, there is no other way than talk to the user in their own language. Tell them in their words what you can do for them, how it will work, and what the outcome will look like. Don't lie to the first-time user, not even by omission or obfuscation. Don't take for granted that they have heard of your thing before (because your product / site / system is such a success!), and thus, know what things are called in your world. No, be respectful to the first-time user.
Oh, and, BTW, if you do that, you will find that, suddenly, your system becomes much easier to maintain. Why? Simply because a developer that goes back to code (which is in fact only the back-side of the interface users see) is very much like a first-time user (even in their own code)! So, if you have made things easy and amenable to first-time users, there you have it: it's also easy and amenable to developers who maintain and build on your stuff.
Now, we, as a community of users, are evolving in funny and strange ways. First, we are so routinely exposed to lies (in various and at times subtle forms: omission, obfuscation, etc.) in our interactions, that we have come to think it's just normal: we expect—and thus, accept—truth-discovery (simple truth about what a system does, how it does it, etc.) to be a painful, obscure, and time-consuming process. As a consequence, we also believe that becoming a user has to be learned. In contrast, I believe the only thing that should have to be learned is how to become an efficient, power user. Just being usable satisfactorily by a first-time user should be a baseline for usability. Whatever extra comes from training or experience should only increase our ease, efficiency, and/or pleasure at being a user.
Second, as a community of users, we have undergone quite strenuous training, to the point that we have managed to learn entirely unnatural things. Like—classical example—clicking on start to turn off your machine, or looking for quit under the file menu. Unfortunately, this is now part of shared techno-culture, and must be taken into account as part of the innate parlance of users when trying to design naturally behaving systems. But more than anything else, it shows how humans are good at learning, and only suggests what marvels well-directed learning could achieve, if only it didn't have to work against hard-assimilated unnatural associations, and if it built on entirely explicit and honest (meaning “not lying”) interfaces and documentation.
2009-02-05 Thursday ![]()
It just came up for me recently that many of the tools & techniques I don't find very exciting (but some of which, yet, get a lot of hype) are actually “serendipity enhancing” tools. Things that, on occasions, can make chance work for you when you're looking for something. They are ways of presenting or digging into a collection that are hard to explain concisely (and thus, difficult to really leverage optimally, or just even comprehend intelligently), but can have a tendency to pop-up relevant stuff for you a little better than picking at random. In this sense, they can be useful. But I have an impression that they are often misrepresented, in particular, that their real utility and general usefulness are considerably overestimated.
Looked at this way, they suddenly seem more interesting to me. I still think you're in pretty bad shape if they are the only ways you can look for things, but sure, they can be useful. I put in this category collection visualization tools, of course, but also classification and categorization techniques, whether manual or automatic.
I once said classification is a “necessary evil”, in that it generates anxiety for the user (who is afraid of taking a “wrong” branch), but allows us to not have everything everywhere (which, even in our digital era, is still impossible). I still stand by that, but would qualify it a bit. If, as a user, you don't rely on the scheme to find something, but only to help you find it quicker or more easily, then, you are less likely to develop anxiety in front of a choice in the tool, simply because the cost of failure is not as big. If you are lucky, then you are happier. So, it's sort of: if it doesn't work, then, you are no unhappier than before, but if it works, you consider yourself lucky!
I claim the expression “Googlewhack” mildly supports my point of view (at least if the Googlewhack happens to be a useful search, not just intended to satisfy the definition)…
2008-03-30 Sunday ![]() (continued 2008-05-10
Saturday)
(continued 2008-05-10
Saturday)
 Recently, I visited different museums, with totally different goals.
They were all within walking distance (not from one another, mind you). I enjoy
museums, specially when the visit combines with a walk.
Recently, I visited different museums, with totally different goals.
They were all within walking distance (not from one another, mind you). I enjoy
museums, specially when the visit combines with a walk.
The first visit was of the Musée d'art contemporain de Montréal, on February 24th. There was an exhibition of works by (Montreal-born) Arnaud Maggs that interested me. A friend had mentioned it to me around Christmas, and I didn't really think I would have time to visit it, but suddenly, I found myself walking in the vicinity of the Museum with a couple of hours at my disposal. The exhibition included, among other works, a series of photographs entitled “Werner's Nomenclature of Colours.” It actually consists of photographs of the pages of a book (with the same title) published in 1814 by Patrick Syme, a Scottish floral painter, an adaptation of mineralogist Abraham Gottlob Werner’s original 1774 work, expanded to include the animal and vegetable kingdoms.
 What
I find really interesting is the whole idea of a “nomenclature” of
colors, from Werner's original work, to Maggs' rendering of it, going through Syme's
adaptation. I find it quite fascinating that experts in the professional use of
colors would feel the need to name colors, rather than just show them. To
me, this illustrates the power of, and need for, verbal language when it comes to
reasoning in systematic ways, and maybe collectively, about human activity. I bought
the program, which includes (as the exhibition does) a full reproduction of Syme's
original nomenclature.
What
I find really interesting is the whole idea of a “nomenclature” of
colors, from Werner's original work, to Maggs' rendering of it, going through Syme's
adaptation. I find it quite fascinating that experts in the professional use of
colors would feel the need to name colors, rather than just show them. To
me, this illustrates the power of, and need for, verbal language when it comes to
reasoning in systematic ways, and maybe collectively, about human activity. I bought
the program, which includes (as the exhibition does) a full reproduction of Syme's
original nomenclature.
I visited many other museums in Bergen (Norway). Those visits were for family leisure. As can be seen from the picture, we were totally off-season, and had delightfully quiet experiences. We visited a Picasso exhibition (including a great guided tour), a natural-science museum, the hanseatic museum, and several others.
The natural-science museum includes a vast collection of stuffed real animals. This sounds a bit old-fashioned and, in fact, I doubt such a collection could be built nowadays. It would probably be regarded as unacceptable (and maybe disrespectful) to kill animals for the sole purpose of stuffing them and displaying them to humans. I don't know exactly what to think of that, but I can assure you that I enjoyed my visit, and I am sure it's not all negative for people to be able to see these beautiful (and not so beautiful) animals, even dead and stuffed.
2008-02-16 Saturday ![]()
Ouf! Where should I start? Maybe with a bit of historical setting. On my Dell XPS M1210 notebook computer, bought in July 2007, was a sort of “demo++” version of Roxio Easy Media Creator 9 Suite. Late December 2007, I wanted to create a video DVD (my first one), and soon discovered that my installed version was crippled beyond imagination, with many functions actually listed in menus, but not working, and in general zero customization possibilities (the doc had a general disclaimer stating approximately that “some functions might not be available depending on the version you are using”, but a cross-ref table giving any detail on that was nowhere to be found). After fiddling around a bit with my crippled product, as well as with Microsoft Movie Maker (which also came preinstalled on my computer), and doing some basic research, I decided to take advantage of an offer from Roxio to upgrade to a true (and hopefully not crippled) product. By then, the current version was version 10, so I ended up downloading a paid version of the full Roxio Easy Media Creator 10 Suite (EMC) product in January 2008.
At this point, a couple of annoyances: the product comes in the form of a two
(gigantic, 750+ Mb each, the size of full CDs) executables:
RoxioEMCSuitev10_4737GA50R05.exe and
RoxioContentCDv10_SQA.exe. Impossible to “officially”
know what each one does, whether they should be both executed, and in what order: no
doc, no info on the Web site, no support. I had to guess. Since the first one
sounded more like the real thing, I picked it up and it turned out I was lucky. To
this day, I have never touched the second executable.
Don't execute the executables directly! If you do (as I first did), later installation modifications from the configuration pannel will not work, with some “network accessible files” being “not found” (wow!). And believe me, you will want to modify your installation, be it only to get rid of dead weight. So, instead, uncompress the executables to a folder, and then execute setup from there.
From the time you install EMC, you will not be able to read DVD's with Windows Media Player (WMP). Some cowboy component (probably CinePlayer) must step on some registration of some kind; anyhow, you'll get an error message (totally off, talking about your screen resolution, but that's not the point) when you try to read a DVD with WMP. (BTW, I know it is EMC that causes the problem, because I did many successive installations that I reverted with system restores, and WMP failed to read DVD's exactly when EMC was installed.)
I chose to cope with such an infamous behaviour because I have MediaDirect on my Dell, and can use it to read DVD's (it is not screwed by EMC). But in general, this might not be acceptable. Be warned.
When you're ready to burn a video DVD, comes a critical step in the process called the “encoding” of the movies. How this is performed depends in part on the “Project Settings” (File menu in the MyDVD application). At least with some movies, if “Interlaced” is selected in those settings, the encoding shamelessly hangs on you and you have to kill the application by hand (in the task manager). After hours—if not days—of trial and error, I found out that if I chose “Progressive” instead of “Interlaced”, it didn't hang!
Here is a small annoyance, but worth mentioning: in those “Project Settings”, the default video standard right after installation seems to be PAL, not NTSC (at least, it was in my copy of EMC, even though I purchased the English version and am located in North America). If you leave it to PAL, you will probably be able to read your DVD's on computers, but not on north-american home DVD players. So make sure NTSC is selected, unless you positively want PAL.
This is the one I just can't understand how they ever let a product out the door with. It happens when you create a DVD with more than one movie on it. In my case, each movie also had multiple chapters; I don't know if it would happen with unchaptered movies. The problem is that launching a movie from the main menu will make it start somewhere in the middle rather than at the beginning, except for the first movie, which starts correctly.
After hours—if not days—of trial and error, I finally found out exactly what happens: it is simply that movie number n is started from its chapter number n. When n=1 (the first movie), everything is fine, the movie starts from the beginning. However, when n>1, the movie starts in the middle (movie number 2 starts from chapter 2, 3 from 3, etc.).
The only workaround I found to this is to insert dummy chapters at the beginning of all movies except the first one: (n-1) dummy chapters are inserted at the beginning of movie number n. Personally, I use color pannels as dummy chapters. Documentation and error messages are unfortunately not consistent about the possible placement of chapter markers. It seems, however, to be the case that chapter markers must be at least 5 seconds from the start of a movie, 15 seconds from the end, and 2 seconds apart (those seem to be video DVD architecture constraints).
Needless to say, I had enormous amounts of frustration installing EMC and getting it to do useful work. Especially considering that support is zero (I won't insult you by mentioning “RoxAnn”, a brain-dead online agent which they apparently think you can do something with—that's probably because they never tried it).
At this time, I have worked out by myself workarounds to the major bugs encountered so far, so I finally decided to keep on using EMC, at least until I discover bugs I can't handle. But EMC is not a good product, and support is inexistant. If you are not as stubborn as I am, it's probably not a good choice.
If I can save anyone from the hassles I went through with EMC, my goal will have been reached.
2007-01-19 Friday ![]()
What is “content-oriented HTML?” Essentially, it is HTML (or XHTML) in which you decide what to mark up based on presentation needs, but how to mark it up based on semantic properties of content. It necessarily entails separation of content and presentation, and thus, the use of CSS stylesheets. There is some limit to the level of control you can have over presentation with content-oriented HTML; there are presentations you just can't achieve while strictly adhering to the approach. But you can go a long way in controlling the presentation, even if your markup doesn't serve specifically that purpose.
Why bother? Why would you want to do content-oriented HTML? Essentially for one big reason: with content-oriented HTML, the “raw content” of your HTML document is augmented, not with presentation instructions by and large irrelevant to what the content means, but with more of what the content means. The resulting document will tell more in the line of what your content is trying to say, rather than more in the line of how to lay it out on a screen or on paper. In some circles, we would say your document is more intelligent; it bears (or conveys) more understanding of some situation or phenomenon in the world or in someone's imagination (in the case of fiction works).
Schematically, one could write:
And what does that big reason buy you? Well, various things. For example, with the proper tools, you could perform more accurate searches for information in your documents. Or extract automatically more meaningful information, from which you could produce more informative reports, or build tables or databases that you could manipulate further to derive more information (statistics, for instance). People who practice content-orientation (be it content-oriented HTML or any other form of content-orientation) can't seem to find an end to the advantages it has when it comes to processing their information. One could sum up these advantages by saying content-orientation makes reusing information easier. We'll keep it to that for here, but chances are, if you give it a try, you'll find your own advantages to content-orientation.
Of course, if all you want to do is produce a single document, without ever reusing the information you put in it, then content-orientation is an overkill. It's just not worth it. However, in the setting of organized business and the corporate world, it is rarely the case that you want to produce a single document with no form of reuse whatsoever in sight.
It's actually not too difficult to do content-oriented HTML. Here is the general “receipe”; we'll comment on it later:
<div> or <span>, depending on
whether the corresponding parts should be displayed as paragraphs of their own
(in which case, you should choose <div>) or be flowed in
the same paragraph as the surrounding parts (in which case, you should choose
<span>).<div> and
<span> have empty definitions).class= the class name worked
out in (e).After that, you need to define your CSS stylesheet with the appropriate rules for
rendering the elements with the classes worked out in (e) as you want them to be
rendered. You also need to link your HTML document with your stylesheet with a HTML
<link> element.
A few comments are in order:
<em> for parts on which you want to put
emphasis, even if you want the rendering to be a bigger font, rather than the
default italics.<strong>, because its definition is strong emphasis.
However, you could use <em>, the definition of which is simply
emphasis. Then, the “differential” remaining to be taken up
by the CSS class name would be light. Thus, you would use element
<em> with a CSS class of light, that is
<em class="light">.Doesn't content-oriented HTML boil down to using CSS to control the presentation of HTML documents? Not quite; it involves more than just CSS.
Even if you use CSS, you could pick class names that are not content-oriented. For
example, suppose you decide to use <span class="red">
for important passages. Since you are using CSS, you get content / presentation
separation, which would allow you, for instance, to change presentation decisions
without touching your documents. But your markup is not reinforcing the content; it
is actually presentation-oriented.
By the way, presentation-oriented markup together with content / presentation
separation can actually make your documents “lie.” For instance, if you
change your decision about how to render <span
class="red"> passages, and make them appear, say, with a
bigger font, and do not change your documents, then the documents are actually
lying. Indeed, they are “promising” passages in red, but what you get is
passages in bigger fonts.
Can you push the logic of content-orientation further? Yes, in the following way: you can decide what to mark-up based not only on presentation needs, but also on other foreseeable operations to be performed of the documents. For example, you can take into account various document management operations, such as classification, filing, application of a retention schedule, etc. Or the production of statistics (which employees generate the largest number of memos, etc.). This affects only the identification of what has to be marked-up explicitly. Once you have established that, you decide how to mark-up things exactly as presented above.
One advantage of content-orientation is it can usually be done incrementally. If you start by marking-up passages that need special presentation in your documents, and later decide to mark-up more passages, based on other considerations, chances are the new mark-up decisions will not interfere with the earlier ones. All you will have to do is add markup in your documents, not remove any. Your document will simply become more and more “intelligent”, in the above meaning.
2006-12-12 Tuesday ![]()
Why are people so fond of talking? Gregarious nature of the human being, you will say. Of course that explains a lot. But not all. In many circumstances where one should think people would strive for conciseness, speed, and bare-bones communication—that is, where one should think the gregarious effect is null, or close—, even in many such circumstances, people will expend the effort of talking, with apparently no perceivable benefit (not even a gregarious one, by the hypothesis just stated).
My research assistant told me recently of a story that is as funny as it is revealing of the phenomenon. A guy, apparently somewhat in a hurry, enters a drugstore to buy breast milk substitute for a 3 months old baby. Quickly enough, he locates the right shelf, and on it, a can that looks like what he wants. The label reads: “Infant formula. Suitable for infants aged 0 to 6 months.” What a hit... can't be more on target than that, can you? Let's see...
He calls an employee! “Is this OK for a 3 months old baby?” he asks.
– “I think so... What does the label say?
– It says ‘between 0 and 6 months’...
– I guess it's OK, then... Do you want me to ask the pharmacist?
– Yeah, thanks, I'd appreciate it... You know... wouldn't want to have to come back!
– Yeah, I understand.”
Pharmacist joins the party. “How can I help you, Sir?
– I need formula for a three-month-old; is this OK?”
Pharmacist has a look at the can.
“Yes, that's exactly what you need, Sir!
– Great! Thank you very much! Have a nice evening!”
(Pharmacist and employee in chorus) “Same to you, Sir.”
What can we make of this? We are not in a situation where small-talk is of the essence. It is clearly not out of an urge to communicate with his likes that the protagonist engages in a conversation. My theory is that it is out of disbelief and distrust that the guy acts like that.
How could that be possible? I think it is because we all have grown used to being shamelessly lied-to, to a point that we instinctively distrust all but the most routinely and repeatedly used sources of information. Not lied-to in a litteral manner (at least, not often), but in the subtle and pernicious ways mentioned in the previous entry. So much so, that we become suspicious even when the meaning of something is actually downright clear and unambiguous. We develop a reflex of distrust with some sources (software interfaces, to pick a random example), that we apply to other sources (infant formula cans).
But our distrust is not that enormous. Had there been no employee around, our guy would probably not have gotten through the trouble of looking for one, at least not for very long. So here is how it goes, in my view: Some given thing (communication artefact) is clear. Still, we experience an instinctive and vague sense of distrust. If at all possible, we will try to dissipate that uneasiness by engaging in a dialog with someone who should know better. However, if doing so would cost too much (in effort and/or time), then, we beat the instinct and force ourselves to reason: “Come on, this has got to be true: think of the context and of the source!”
I see it all the time, during exams (that I give): Most of the time, my questions are clear. Even when a question is crystal clear, a lot of students feel an urge to come and dialogue with me. A “I am pretty sure that's what it means, but am I right? – Well, if you mean ‘blah-blah’, yes, you're right. – Yeah, that's what I mean. – OK, then you're right!”-kind of dialog.
Of course, most students don't come talk to me during the exam (a lot of them do it afterwards, mind you!). Why? Because the amount of self-confidence it takes to stand up during an exam and go talk to the professor exceeds their sense of distrust. So, most come fairly easily to their senses and simply believe what they read in the questionnaire. Certainly in part because they know that I am usually a rigorous person (how badly do they know me! 8^), and that if I write A, I mean A, and I am not going to change my mind the next minute. Even more so in the context of an exam question. So they overcome their sense of distrust, and quietly go on with the exam.
2006-10-31 Tuesday ![]()
Sometimes, a piece of information on a screen is so imprecise and/or out of context that it either is impossible to make sense out of it, or showing it in that way virtually amounts to lying to, or hiding facts from, the user. What can a designer possibly have been thinking of when imagining such a screen? Either nothing, or something in the line of: “users don't care; they don't want to know!”
Well, to me, this attitude is totally undefendable, equivalent to saying, with respect to the fineprint on some legal documents: don't remove it, it's got to be there, but don't make it readable, people don't care, they don't even want to know, YOU don't want them to know. It might be true that most people don't care, but if society has made it a rule that the fineprint must be there, then it is—to my eyes—a simple matter of decency to make it readable in some way by all users, be it with a zoom-in function, activated on demand. But accepting that the stupid text be lying there, unreadable to most people, want it or not, is socially irresponsible and, hence, unacceptable.
Let me give an example—a non-legal one. Suppose you design a system for managing information about musical pieces. You might choose to have an element of description called “genre.” Now, imagine a first-time user to whom you display the record of a piece bearing the mention “classical” in the “genre” field. If the user is particularly keen on musical genres, perhaps intending to base her resource discovery endeavors on that field, there are at least three fundamental questions that she will ask herself about the concept of “genre” in this particular system:
This last question is very important, because it determines a lot of what it means for a piece to be filed under a particular genre. The two first questions are also very important, but we will make our point with just the last one.
The answer to the third question is possibly long; indeed, in classical librarianship parlance, it amounts to giving the indexing policy underlying the system. Much like the fineprint in an insurance contract, right? That's exactly the point; most designers would tend to say: don't bother showing that to the user, they don't care, they don't want to know. YOU certainly don't want to go through the trouble of formatting that information and linking to it from the interface (anyway, we don't have a definite policy, we just put the field there, wondering what people might put in it...). It will use up screen space, users will wonder what it links to, they won't understand the document if they ever follow the link, and we'll get lots of questions.
Still—and this is crucial for our point of view—there remains that, if we want to make the most out of our “genre” field, without extrapolating too much on what it means (making it “lie under pressure”), we need to have the answer to question 3 (and to questions 1 and 2, of course). It does not mean that there needs to exist a definite indexing policy, it just means that whatever policy there is—or isn't—, there should be a way for the user to find out.
For example, if there is no policy for the field—if indeed the designers just put it there wondering what people would make of it—then there must be a way for the user to find out just that. Then, she will know exactly (or at least, approximately, which is infinitely better than not at all) how much (or how little) she can squeeze out of the field, in terms of meaning.
Again, the usual attitude from designers is: don't bother; users will find out after a while that they can't rely too much on the “genre” field (or, on the contrary, that they can rely on it), but we don't need to tell them; they wouldn't care. Besides, we might eventually modify our “genreing” method, and then, we'd have to change the online description of the field. So let's not put a description online in the first place. Giving a couple of examples next to the field name might be a good idea, like this:
Genre (classical, rock, jazz, etc.):
Then, users will know what we mean by “genre.” But anything more would be too much.
Of course, I don't share that point of view.
The point of view that I propose and defend, is quite simple. It can be expressed as follows:
In our analyses of/discussions about information-bearing objects of the world, it is profitable to envision those objects as having “text-only” equivalents. Then, the key communicational properties of those objects (like consistency, clarity, completeness, unambiguity) translate into natural language (NL) properties of the text-only equivalents. We claim that communicational properties are more easily, clearly, and quickly assessed with the text-only equivalents than with the original objects.
It follows from this point of view that efforts for improving the communicational effectiveness/performance of information-bearing objects should proceed along two lines: discovering the non-NL to NL translations that users naturally and instinctively perform in the usage context of the objects, and designing the objects in such a way that applying those translations to them yield NL-equivalents that are communicationally efficient (clear, efficient, and coherent vocabulary, style, and writing in general).
By and large, what we advocate could be labelled “litterate design”, akin to what Donald Knuth's litterate programming is to programming in general. Let design be envisioned as an act of litterary creation! Why couldn't the two meanings of the word “style” converge in this unified view of design and litterary creation?
For example, if we envision each interface element of a system interface to have a text-only equivalent, we will come to see the interface as speaking to the user. Most people would probably not go all the way and say that the interface is actually speaking to the user, but would probably agree that it does so in some metaphorical sense, through some semiotic system that is a combination of iconic, textual, and geometric, but certainly not in natural-language. In contrast, our point of view allows us to consider that the interface is speaking to the user very concretely, in natural language sentences, or at least words. Then, any defect in the design or coherence of the interface will become obvious, by the mere fact that the sentences spoken by the interface to the user will be either ill-formed, contradictory, unacceptably incomplete, misleading, or simply lies (untrue).
Interfaces are information-bearing objects, but there are others. Databases are an example; structured documents, another. So our point of view can shed new light not only on interface design, but also on database design and document modeling. In fact, our approach leads to a general semantics of structure, that can be applied to the design and analysis of virtually any type of systems delivering information resources and/or services, what we call informational systems. Examples of such systems include road-side signs, TV commercials, books, interactive electronic technical manuals (IETMs), public libraries, and automatic teller machines (ATMs).
In the domain of information modeling (or information architecture, which includes database design and document modeling), our approach has a specific benefit: it provides a common ground, a pivot language for discussing the relative merits of fundamentally different models such as textual databases, relational databases, and structured documents (SGML, HTML, XML, etc.).
A further twist to our approach is the assumption that, whatever parallelism there might be in the actual geometric presentation of the information-bearing elements of an object, the user/reader always reconstructs some sort of sequentiality among those elements. In our view, then, the efficiency properties of the total object can be assessed by considering the natural language properties of the resulting text-only equivalents of the whole object under all possible sequential reassembling of its constituting elements.
Finally, we note that, in general, information exchanges between a user/reader and a system are not isolated, but naturally occur as sessions of interactions, that unfold in time, constituting in our language view a dialogue. Thus, in our approach, we are drawn to analyze not just the efficiency of each information exchange as a natural language sentence, but also of the whole unfolding of interactions, as natural language dialogues.
What does sex have to do with any of this? OK, I concede I fell for the pun (though all I know about the film is its title)! But sex does have something to do with this!
If we apply the natural language point of view to interfaces that include elements for launching and otherwise controlling operations (which most interfaces do), I bet we will find out that the interface has to address the user in the second (or maybe even first) person. In some languages, such as French, in order to do that with any positive level of elegance and efficiency, you need to know the user's gender. Otherwise, you are lying.
Not in a way that will take you to court, no. But in a way that contributes to obfuscating communication between a system and a user, and that, thus, should be avoided, by any ethical and responsible definition of “design.”
So, if I am right, appropriate user modeling for most interfaces does include sex!
Happy Halloween!
2006-10-03 Tuesday ![]()
OK, it's now. There are a number of things (repositories of some sort, in fact) I have kept “starting” and never quite got to a state where I could do something with them. Well, I've just decided I'm going to show them anyway, cause if I wait till they're ready, I'll wait forever...
For the moment, there are three things. I won't say much about them, but at least link them from somewhere. That way, if there's anything good for anybody, there's at least a small chance that thing and body (any, by their first name) will meet! So, here they are:
Concerning the third resource, it is at present just a bulk of scanned visual artifacts. Please, have a look! Can you tell why I find them “amazing?”
2006-09-20 Wednesday ![]()
Continuing on the idea that annotations are services; how do you take the result of an “annotation round” (which may include application of many different structures on the studied object, then progressive attachment of annotations over time by different people; in other words, discussions/argumentation over the original structure, the suggested structures, and the previous annotations) and turn it into something that can itself be studied, that is, for example, annotated?
I just described the problem in terms of “rounds” of annotations, but of course, a solution in which each single annotation or alternate structure would yield an annotatable object would be even more interesting. For one thing, it would alleviate the need to identify those “rounds”, in particular, decide when a particular round is finished.
Isn't this reification? Yes, but trivial approaches do not seem satisfactory. For example, simple serialization does not appear to be an interesting avenue. In markup terms, that would involve for example, turning a whole document, including markup, as a large CDATA content inside a one-element document. Hardly sounds promising...
I think we should look at multiple hierarchies and overlap in XML in terms of reification. Maybe that would provide hints as to what a satisfactory approach could look like.
2006-09-19 Tuesday ![]()
I have heard many clever people argue about overlap, even about the need for overlap handling in XML, not just how to do it. Right here, this morning, at SDN2006. Then, I think I suddenly got an insight on their incomprehension. Again, it is the NL approach that gave it to me.
Some people see the character string (or material artefact, for that matter) as a basic creation, over which structure is applied, but structure is not part of the work. Then, it makes sense to separate the character string from the markup. Fine. BTW, that's exactly Ted Nelson's point of view for dismaying “embedded markup.” But, according to the NL approach, markup is essentially abbreviations for text segments. Thus, it is entirely natural to admit cases where markup is part of the creation. But, then, in at least most of those cases, I think it is entirely reasonable to restrict the creation to non-overlapping structures.
What is important is not the distinction between textual content and structure: those should be dealt with using a single formalism (which, incidentally, should be natural semiotics, in my humble opinion; natural semiotics is a generalization of natural language). What is important is the distinction between a resource and a service. Documents that keep changing, that never settle to some fixed form (or “cool down”, to use a metallurgical metaphor), are actually services, not resources.
So, I think a big next question for digital edition is: should annotations on existing separate resources be considered resources on their own or services on those resources? My feeling at this point is that the answer ought to be services. The clearer separation would then make it natural that concurrent structures over some given content live in separate objects from the thing whose elements are manipulated by those concurrent structures (the original creation).
I suspect some “causality chain” argument could be used to support this vision (that annotations are services on resources). I like the word “causal”, because it has connotations (among others) of chronological ordering issues (for example, a causal filter, in signal processing, is one that can be realized in real-time, i.e., for which the value of the output signal at time t depends only on the value of the input signal until time t).
An argument against restricting creations to being hierarchical structures might be that deliberate ambiguity (multiple possible readings) is sometimes desired, as in poetry, lyrical works, and the like. But one could argue that the desired effect is precisely that those readings are not explicit in the original stuff, only implicit. Thus, the raw material is indeed intended to be purely hierarchical (often linear, in fact). (What do you think, Denys? 8^)
2006-09-18 Monday ![]()
It just occurred to me that an appropriate umbrella-expression for all the research I have done so far is “usability factors of structured documents” (except for information retrieval in structured documents, but even it might qualify). The point of view developed in my EML2006 paper (which I will call here “NL analysis”, but is called “intertextual semantics” in the paper) yields a unifying framework for many different reflections on structured documents, and I believe they all boil down to being usability factors. I will give two examples.
(1) NL analysis of XML documents sheds light on their usability, and by transitivity, on the usability of their schemas. More precisely, it translates the vague notion of a document (or schema) fitness to purpose (usability) into a NL readability question.
(2) If we go further upstream from document creation than schema creation, we hit modeling methodologies (the processes in the modeler's mind that eventually yield a schema). Again, as hinted at in the paper, the NL approach translates the schema-building problem into a modular-writing problem. So, again, the NL approach aims at increasing the level of fitness to purpose of something related to structured documents, namely, schemas.
As for my work prior to NL approaches (CRGGID, « XML en route... », et al.), it even more clearly fits under the umbrella.
2006-06-30 Friday ![]()
So, Moody's recently (June 14) raised the Province of Quebec's debt (NB: not credit) rating from A1 to Aa3. That's one notch on the scale. Big deal. Since then, Prime Minister Jean Charest has made an unprecedented number of public appearances, and is heard saying everywhere that, for him, that raise is like winning the Stanley Cup. Shortly after Moody's announcement, an opinion pool on voting intentions placed the Liberal Party (the actual government) in first position, a situation unheard of for quite a long time.
Good news? I guess. But for whom? And what does it really mean?
Moody’s defines a rating as it's opinion of the ability and willingness of an issuer to make timely payments on a debt instrument, such as a bond, over the life of that instrument. In this case, the issuer is the Province of Quebec. Not the Government of Quebec. That's a subtle, but important, difference. The Province won't change. Governments can. And do.
That brings me to what the raise really means. IMO, it depends on how many levels of anticipation the suits at Moody's put into their analyses. Surely, they aren't deaf nor blind. They must have sensed that people's dissatisfaction with the actual government is at an unprecedented high. So, maybe they foresaw an upcoming change of government, and thought “This is good news for the province!” Just maybe.
Or maybe Jean Charest is right, and Moody's action is a recognition of sound governance on his part. And they're there, just waiting to bring down the rating as soon as a less responsible government takes power. Maybe. I don't know.
What I do know is that either Jean Charest is hijacking his new rating into political capital, or I am hijacking it, suggesting it could be bad news for him. I guess you'll have to decide...
Bonnes vacances! God ferie!
2006-06-08 Thursday ![]()
Yesterday night, I was watching that crazy (and live!) TV show, which I like very much, on SRC: En attendant Ben Laden. (Incidentally, the phone rang midway through, and I was stupid enough to answer, which made me swear, period, and also that I would never again pick up the phone during that show...) OK, right, so they have that “game” The tricky question of the week: they pick up an interview that's been aired somewhere on TV during the week, and first, they just show you a clip where the interviewer asks a “clever” question to someone. Like a guy whose house just burned down, and he asks him “Are you shaken?” They don't play the answer right away. Instead, the participants (two of the three hosts of the show!) try to guess what the answer might have been... The funny thing is they pretend the question is really clever, and “guess” anything but the obvious answer! In the above example, they would answer something like “Not at all! Hey, I just found a quarter on the ground! Get real! What more can a guy ask for?” Then, they roll the actual answer (which of course is totally predictable), and they all pretend to be flabbergasted by how surprising it is. Get the idea? I just love it! BTW, Pierre Brassard, Jean-René Dufort & Chantal Lamarre are the hosts on that show.
Well, that game reminds me a lot of some questions asked in some empirical research... For example, the crucial question of whether a person is surprised if and only if, and to the extent that, he or she has just experienced something unexpected. I didn't make up that example. It comes from a book chapter by Jan Smedslund, entitled Psychologic: Common Sense and the Pseudoempirical. The book itself is called Rethinking psychology. Roughly, Smedslund says a lot of (if not all) questions addressed by empirical research in psychology in fact get their answer from common sense embedded in natural language, and not at all from the research performed! His approach, psychologic, consists in distilling that common sense in axioms, from which an awful lot of psychological facts can be infered, without any empirical research whatsoever.
WOW!!!
I just love it! Please, read that chapter! And everything else you can lay your hand on by Smedslund.
I don't know much about Smedslund, in fact as much as you can learn yourself on the Web. Norwegian, born in 1929, Professor Emeritus of psychology at Oslo University, officially retired but apparently well alive and kicking! That guy has apparently been the first one to say many no-nonsense things about natural language, psychology, and the two together. Things that one (me, anyway) would think should have been recognized and accepted for a long time... It is SO REFRESHING to see that such ideas exist, and that some people dare formulate and defend them!
A few weeks ago, I had my library order his The Structure of Psychological Common Sense, which I can't wait to read! I have been particularly delighted by a section entitled “Introduction of Undefined Terms”, on page x (which I was able to view, courtesy of Google Book Search). Basically, what he says is simply that to communicate verbally with someone, you necessarily have to share beforehand some sort of common language. Thus, if you have an idea (or anything else, say a formal language like first-order logic) that you believe can be explained to anybody in a given community, it follows that that thing must be explainable in a language that is already common to you and everybody in the community at the time you start your explanation. Now, think about it: if your target community is large enough (encompassing for instance all highschool kids of a given country), then that language must be—and can't be anything else than—ordinary natural language! Simple, right? Well, I've been looking for that kind of statement for over two years, now, and it's the first time I see something squarely and explicitly in that line!
Dr. Smedslund, thank you! I wish so much I could meet you one day! Who knows, even chat in Norwegian... that would be a treat!
2006-05-19 Friday ![]()
Just read an article in Direction Informatique (yeah, it's online; shouldn't be hard to find; left as an exercise). About a big project at Desjardins (a big financial multi-institution in Québec). They moved many thousands of PCs from OS2 to Win2K. What struck me is not specially the project itself (which seems to have gone fine), but the fact that they interviewed the VP responsible for it. Seems like he did all the job. Big picture on the front page. Then, right at the end, he says he couldn't have done it without a great project leader. (OK, I thought he was the project leader!) The one they had was visionary, open-minded, etc. But the VP doesn't even NAME him (or her, for that matter, we don't know that much)!
I'm asking to myself: what did the VP do, in fact? What credit does he really deserve for the project? Regardless of the answer, I can't help thinking we would have gotten a much clearer and faithful picture of the project had they interviewed either the project leader alone, or at least the VP and the project leader.
We shouldn't underestimate the crucial role technical people play in successful IT projects. It is by far insufficient to have a great manager if the vertical gap down to technology isn't closed. The people who really make things happen do not just float in managerland, they invariably act at both the managerial and technical levels. They could be VPs. But in projects that have their own project leader, the key people for vertical gap-bridging are much more likely the project leader than some VP. Let us (and VPs!) give to Caesar what is Caesar's, especially when it is the laurels of a successful project...
2006-05-19 Friday, somewhere between Montréal and
Québec ![]()
Don't get me wrong. I revere blogs. I mean, all interesting blogs. OK, I promise I will revere all interesting blogs... as soon as they... well, show up. Which, of course, they haven't started to do yet, but it's not their fault! Blogs are great; I love blogs. I'm a blog addict! It's just that, well, there aren't that many around... I mean, good ones.
OK, I have to be honest. I think most existing blogs are kind of a pain in the neck. No, really, it's the non-existing blogs that I really, really dig! So, instead of being fashionable and doing a pain-in-the-neck existing blog, I decided to do a gorgeous, great, super-duper non-existing one! And this is exactly what you are beholding! My non-existing blog, a.k.a. non-blog!
Of course, this not being a blog, you won't find the usual blog bells and whistles. Like comments (you can't really comment, although you can send me a comment by e-mail). But there ain't no ad's either, and that's cool!
Enough with starters! Your obligation is to enjoy. Enjoy reading or non-reading, but ENJOY!


![[Valid RSS]](../../valid-rss.png)